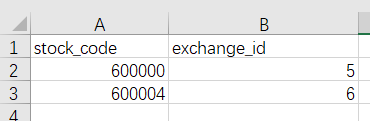Neo4j安装与使用 Neo4j菜鸟教程 Neo4j教程 Neo4j的命令行操作
安装 Neo4j官网下载地址
在Windows上下载桌面版,在Linux服务器上下载服务器版
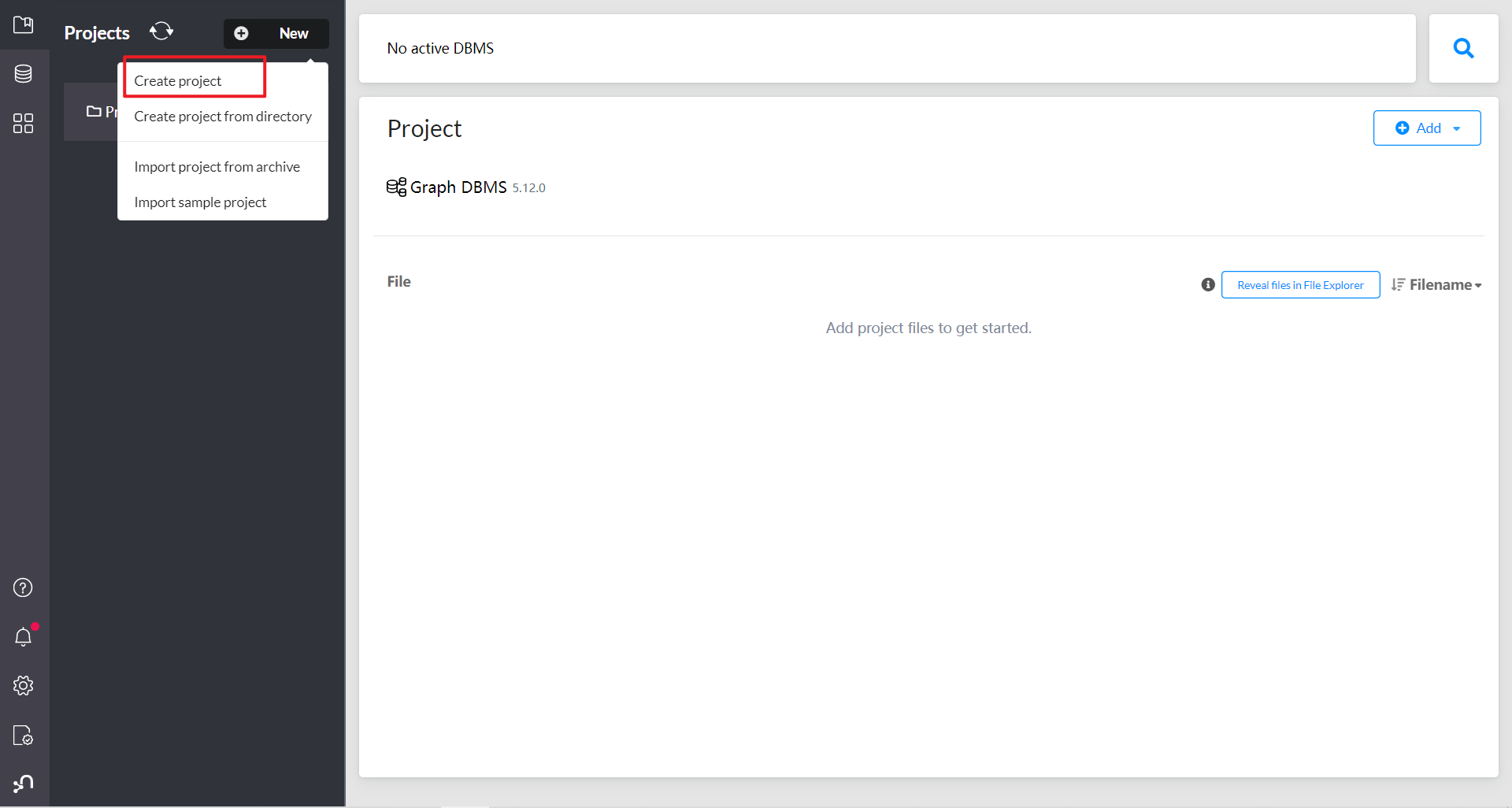
简单入门 点击创建一个新的项目文件
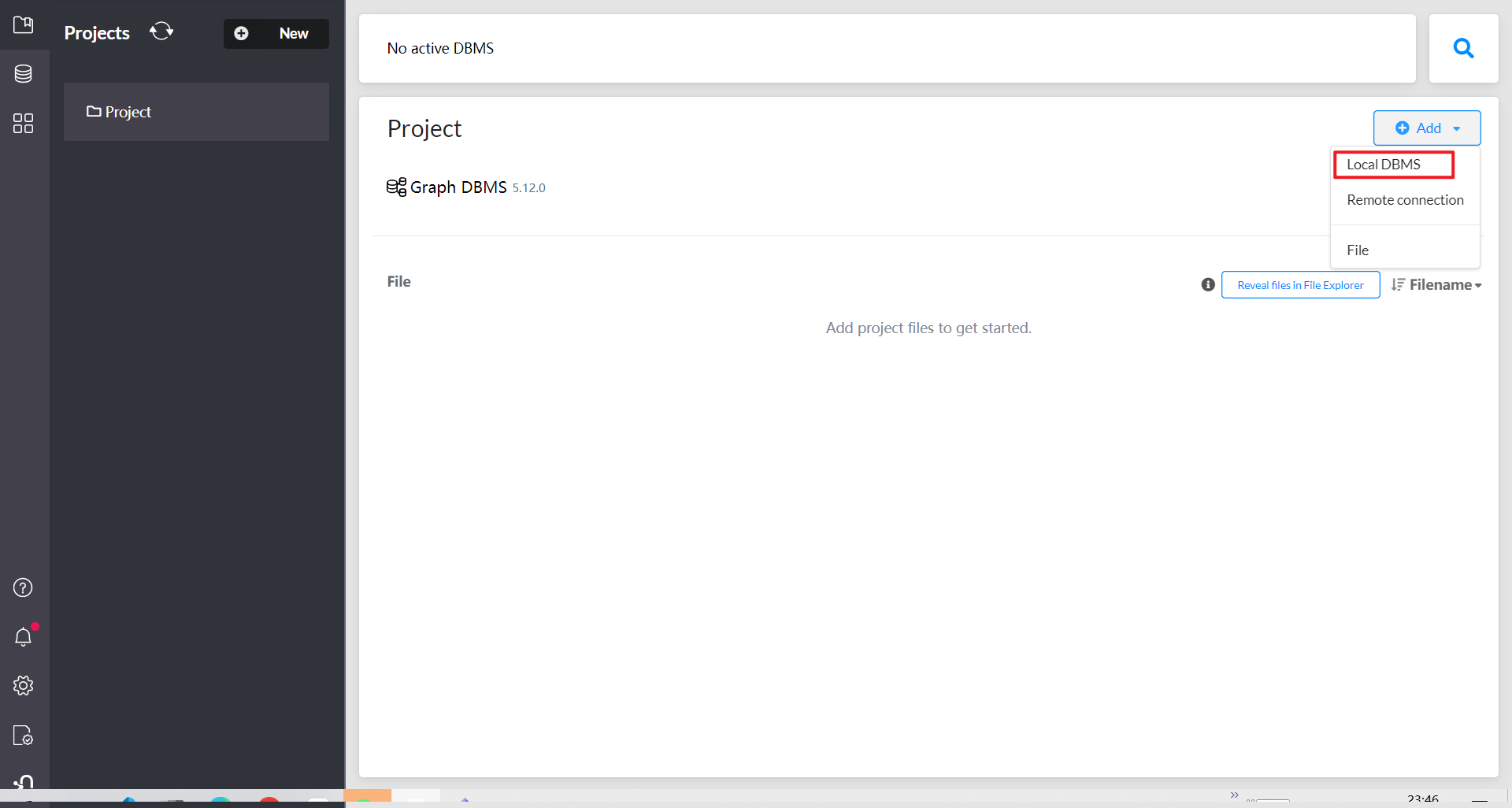
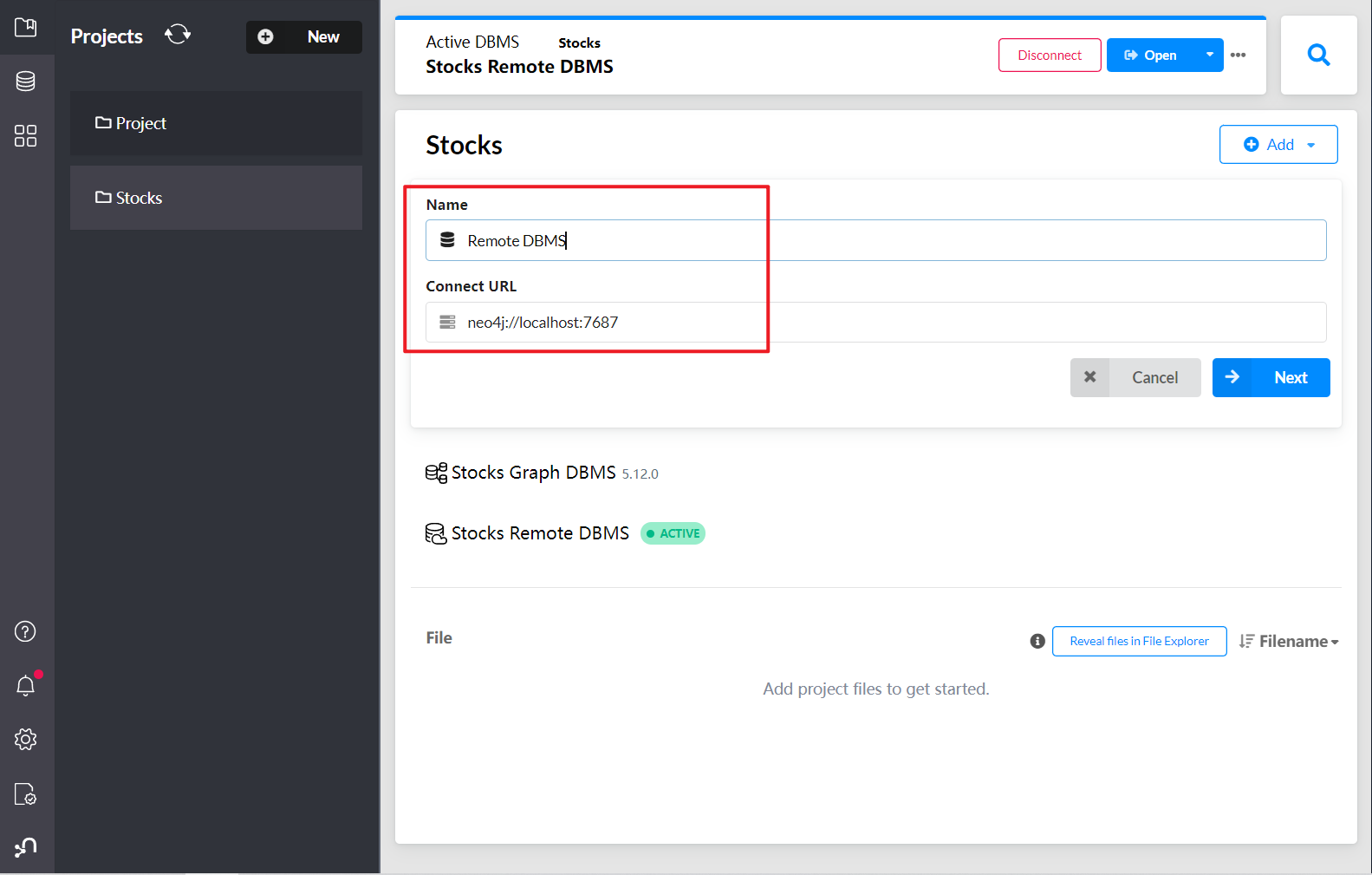
添加一个新的图形数据库
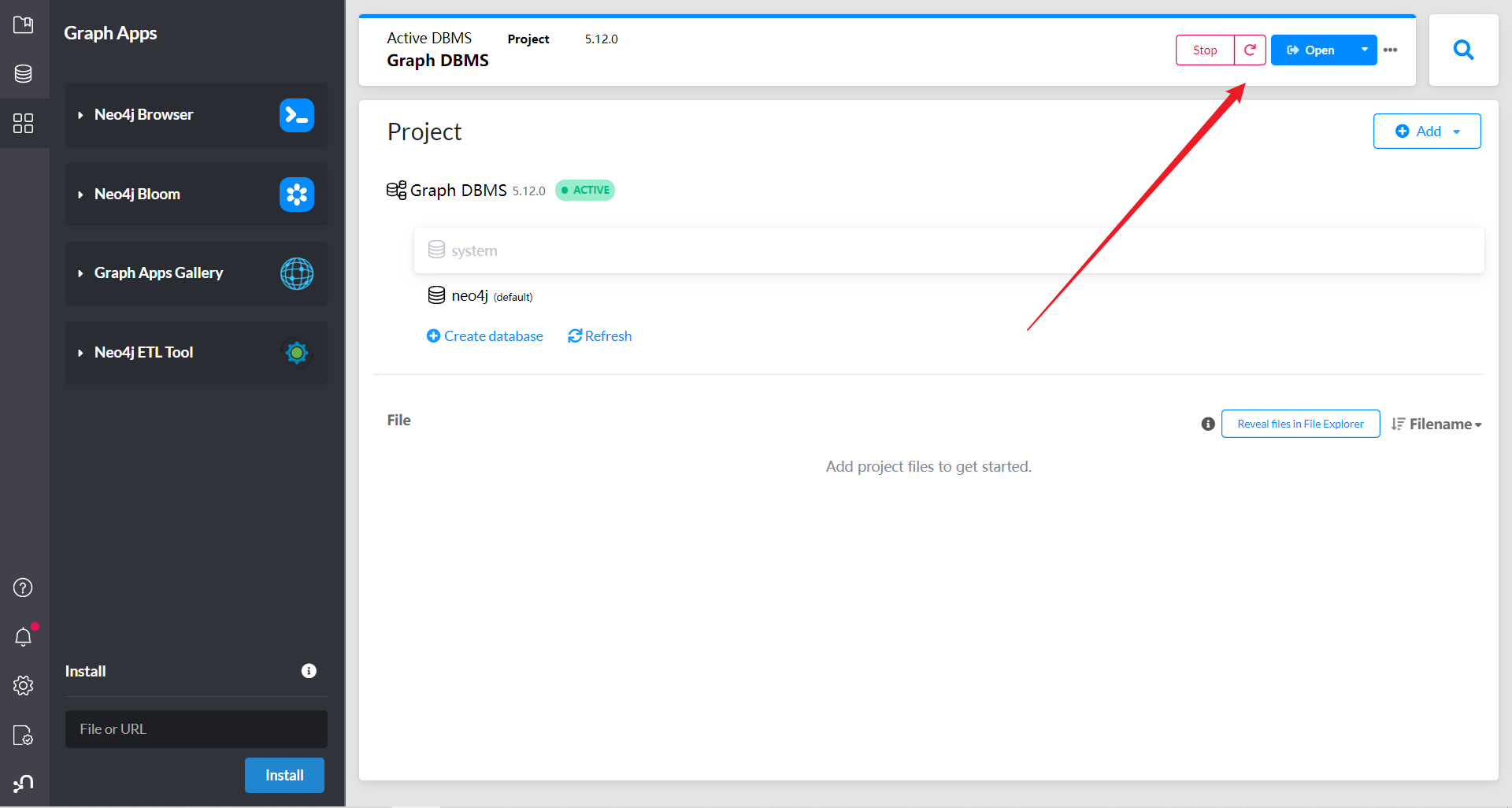
启动数据库
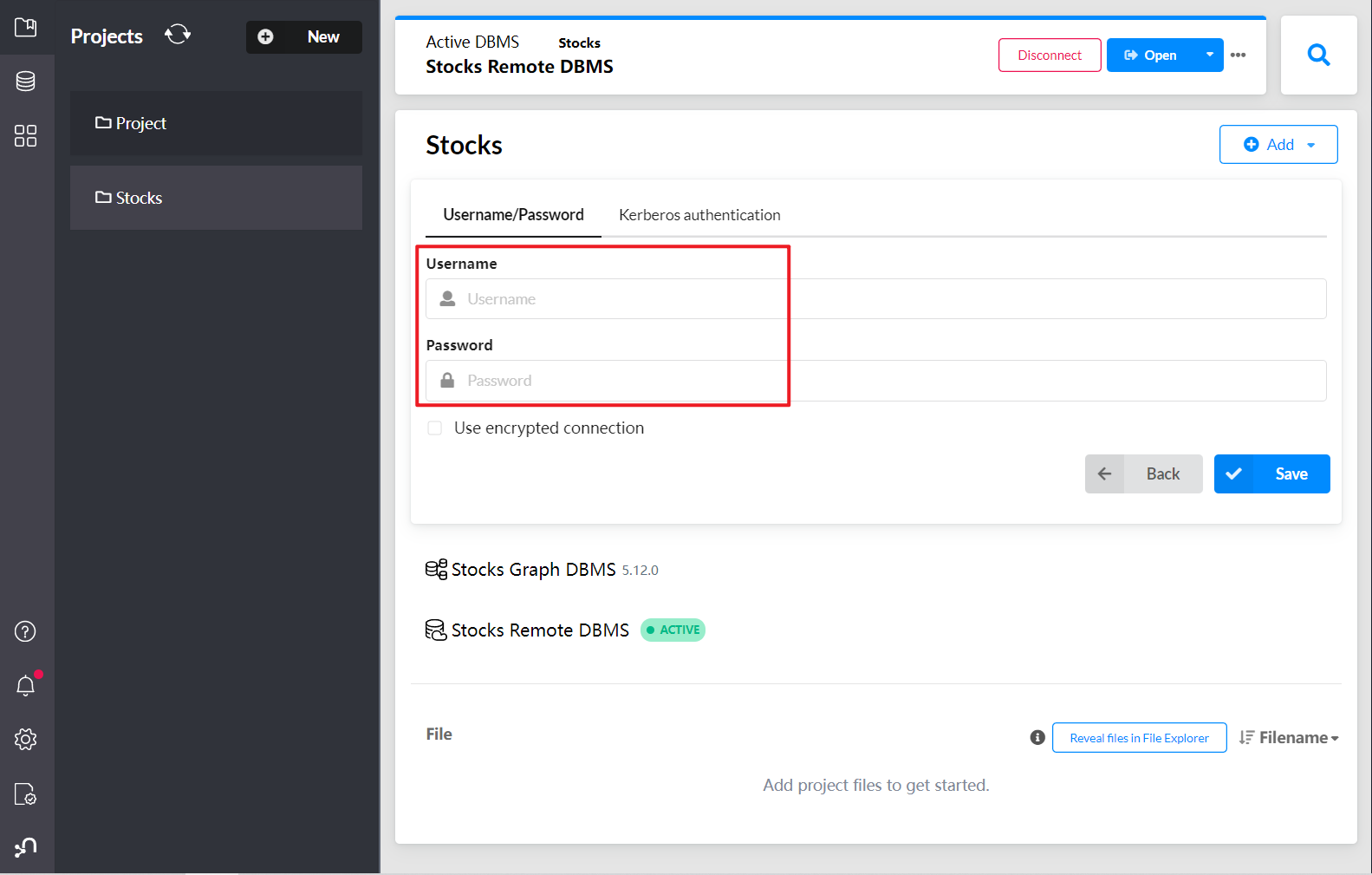
点击右侧应用工具,打开Neo4j浏览器
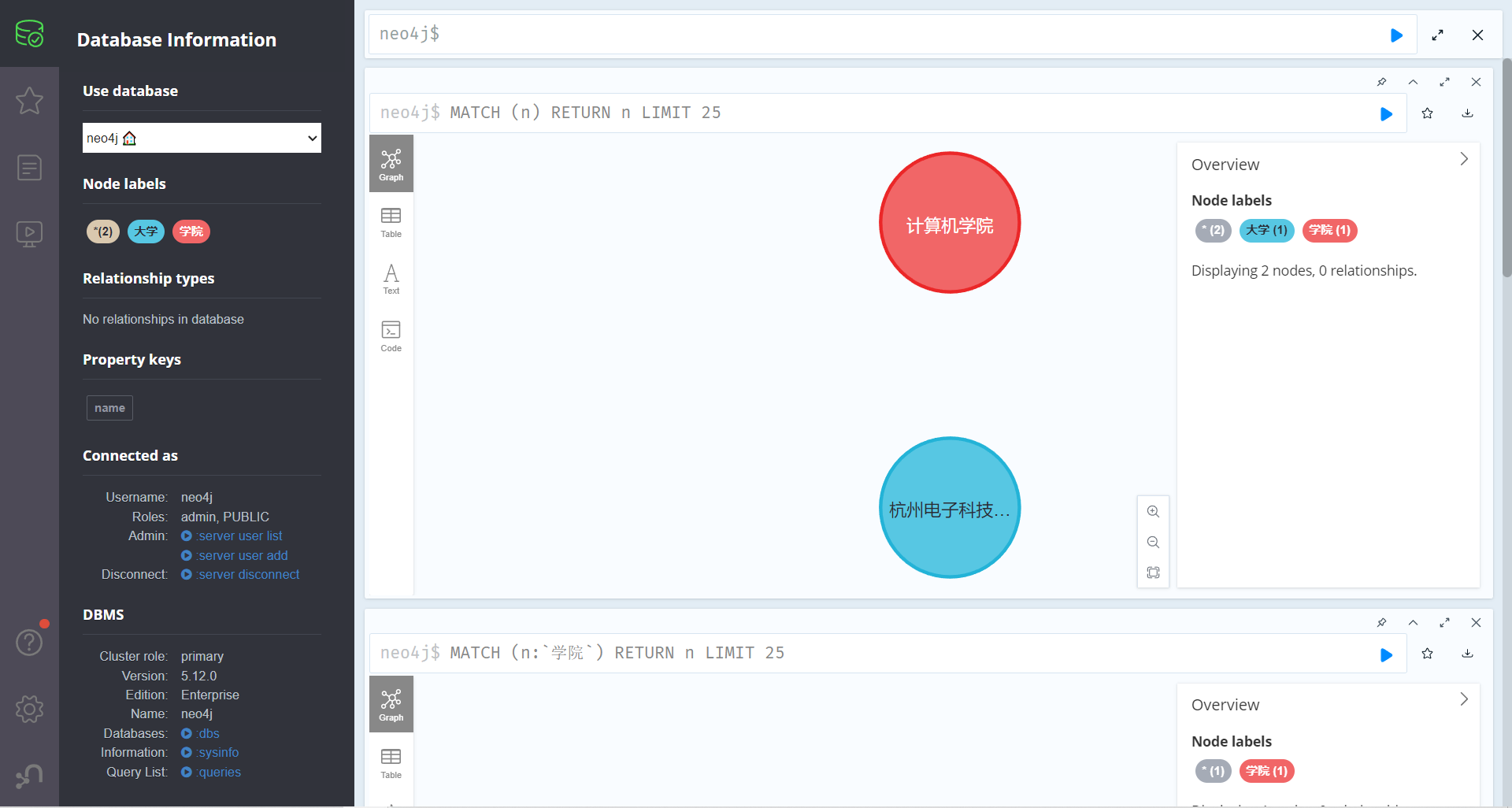
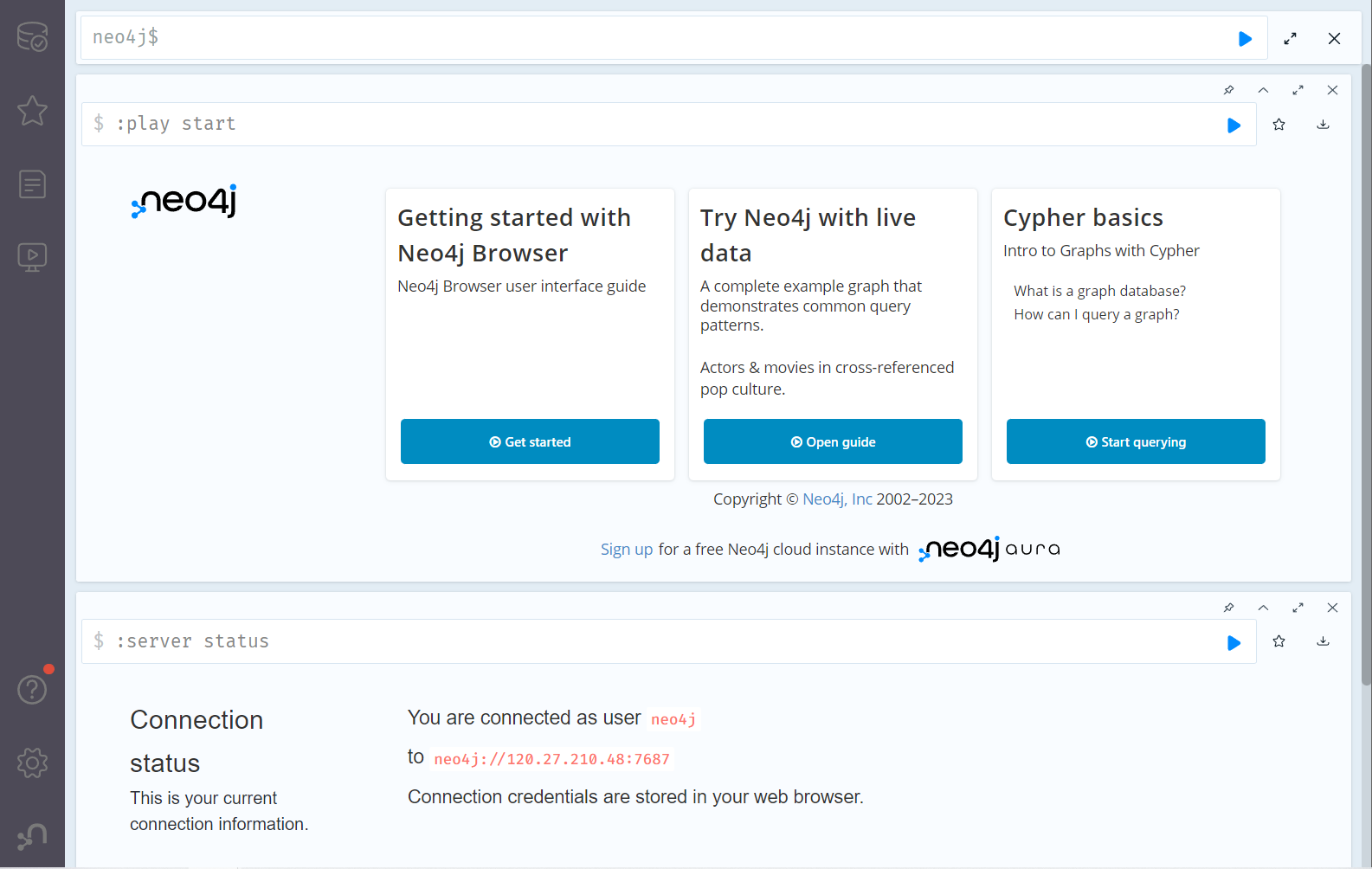
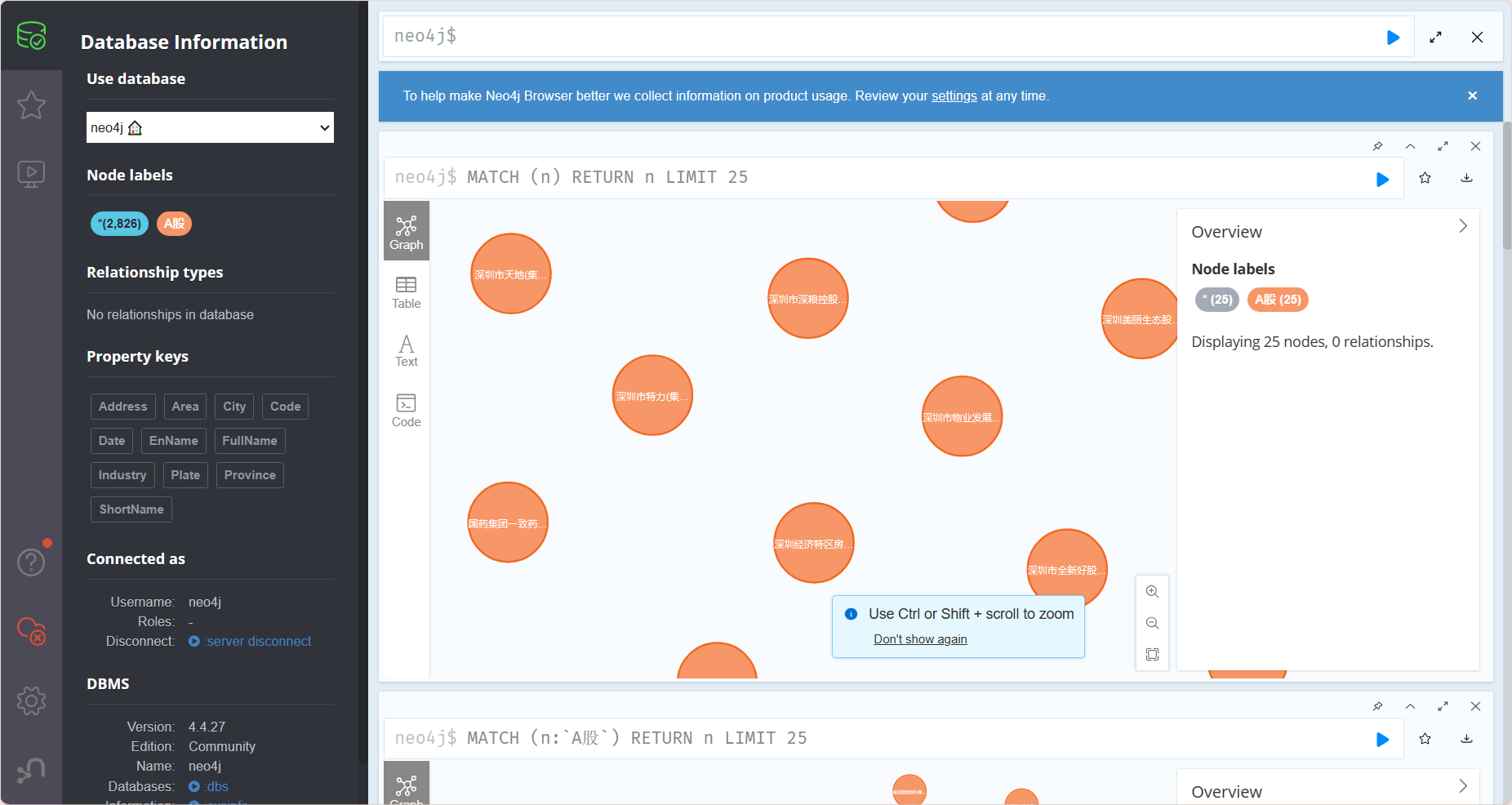
成功链接到数据库,在最上面的命令行中,我们可以执行CQL语句
我们可以通过以下语句创建 杭州电子科技大学 和 计算机学院 节点大学 和 学院
1 2 create(:"大学"{name:"杭州电子科技大学"}) create(:"学院"{name:"计算机学院"})
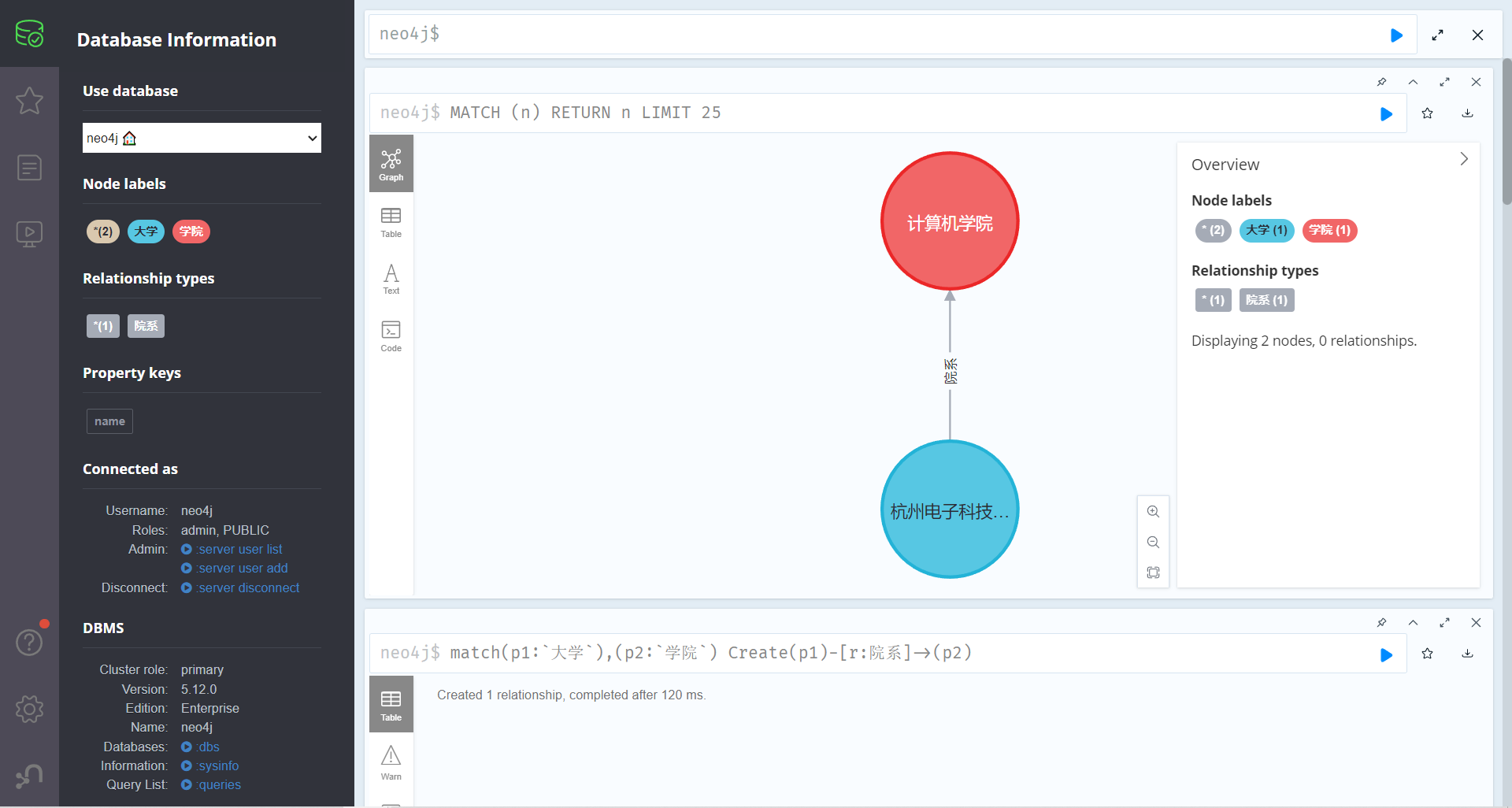
通过以下语句,来将这两个节点进行关系链接语法格式 为:链接两个节点p1 p2,创p1->p2的关系为 院系
1 match(p1:`大学`),(p2:`学院`) Create(p1)-[r:院系]->(p2)
简单案例 1 2 3 4 5 6 创建一个简单的股票知识图谱,包括; 1. 建立几只股票的节点 2. 建立上海证券交易所和深圳证券交易所两个节点 3. 建立省市地方名称的节点 4. 建立股票和证券交易所关系 5. 建立股票和省市名称关系
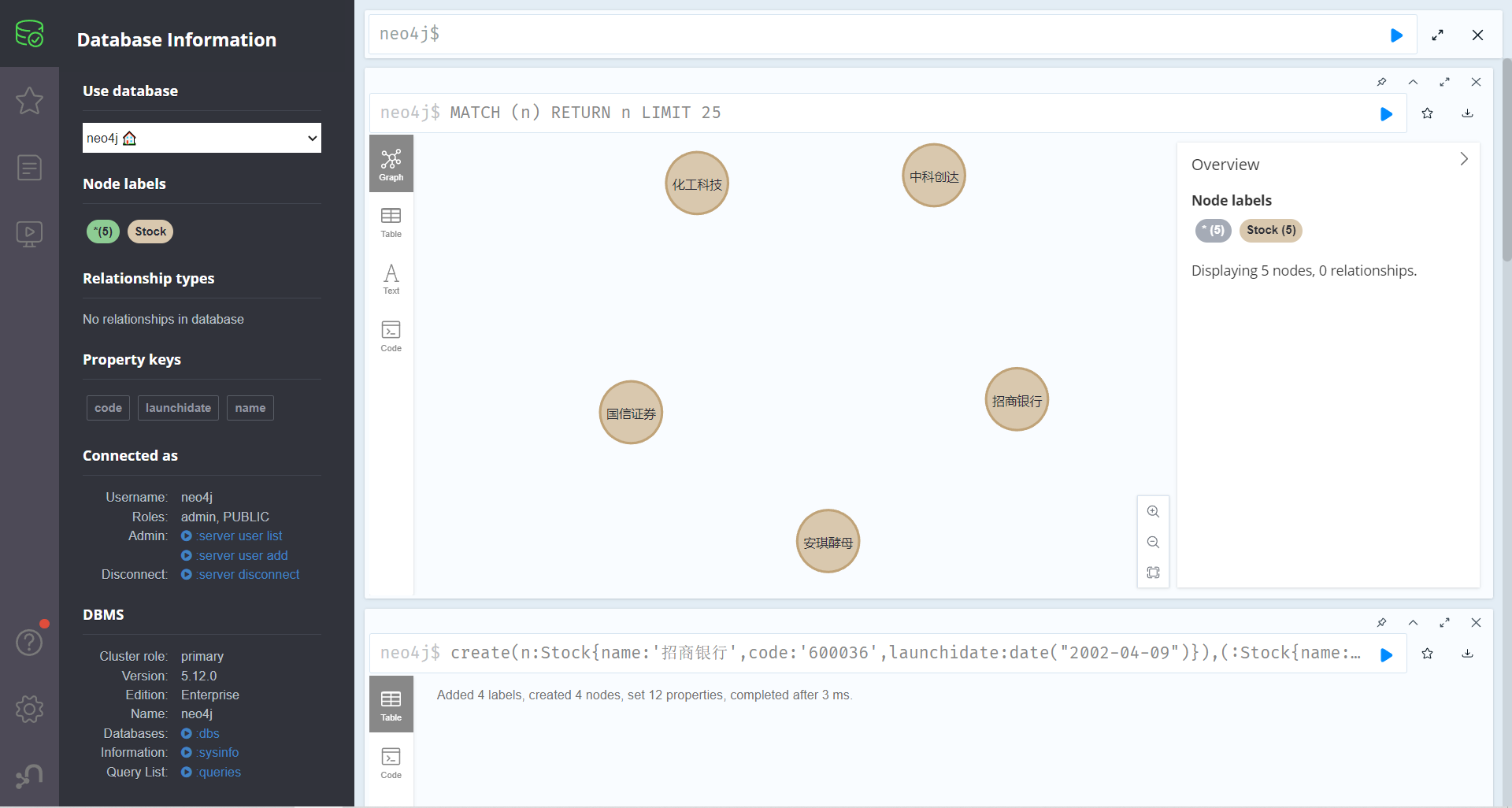
建立几只股票节点
==创建一个节点的Cypher命令==create(变量:标签{属性1:属性值1,属性2:属性值2}) return 变量create(Variable:Lable{key1:Value1,Key2:Value2}) return Variable
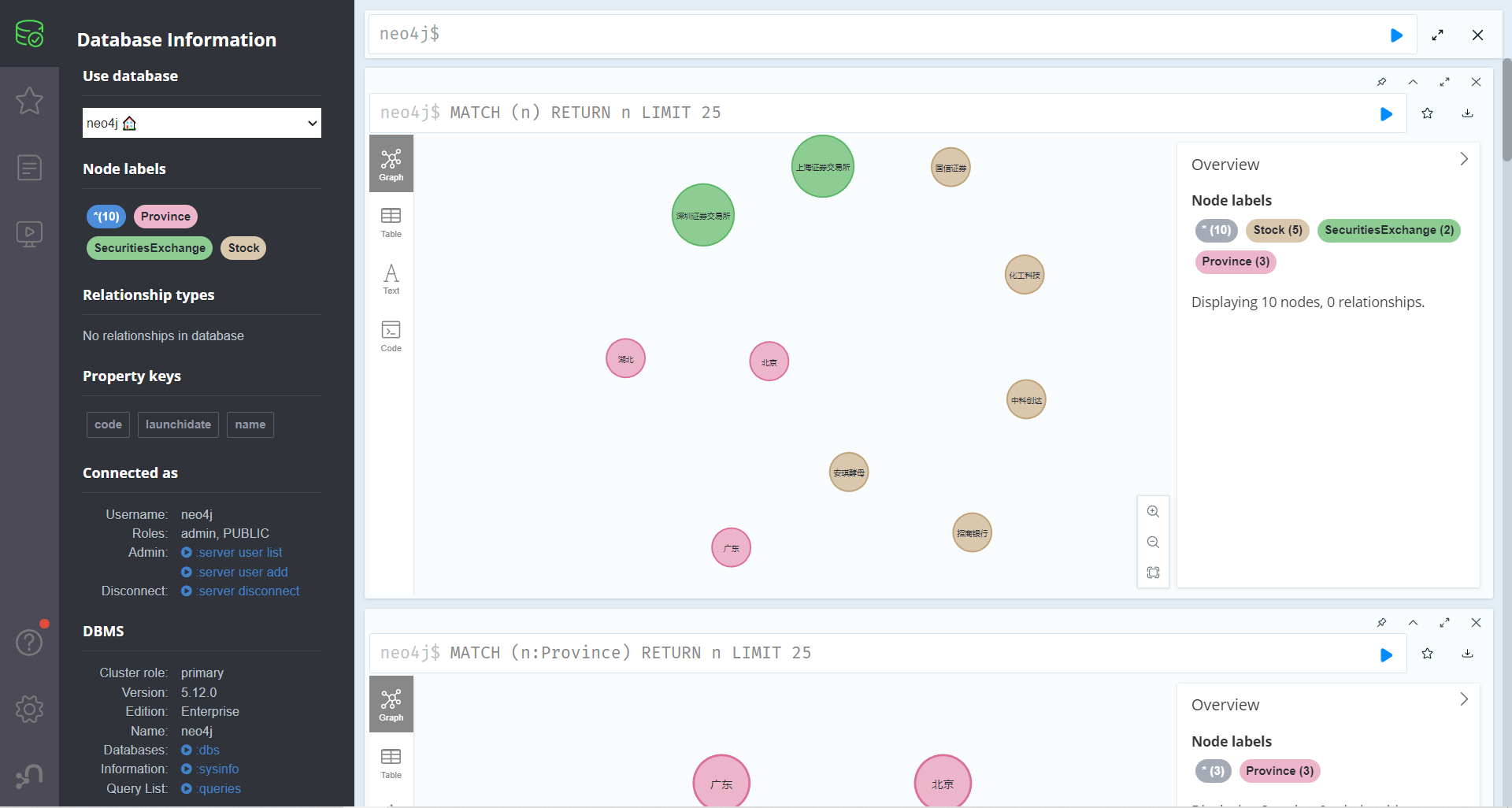
1 2 3 4 5 6 -- 创建一个股票节点 create(n:Stock{name:'安琪酵母',code:'600298',launchidate:date("2000-08-18")})return n -- 可以一次创建多个股票节点 create(n:Stock{name:'招商银行',code:'600036',launchidate:date("2002-04-09")}),(:Stock{name:'中科创达',code:'300496',launchidate:date("2015-12-08")}),(:Stock{name:'化工科技',code:'000988',launchidate:date("2000-06-18")}),(:Stock{name:'国信证券',code:'002736',launchidate:date("2014-12-29")})
按照上方的步骤,创建一个新的股票图形数据库。
建立上海证券交易所和深圳证券交易所两个节点
1 create(n:SecuritiesExchange{name:'上海证券交易所'}),(:SecuritiesExchange{name:'深圳证券交易所'}) return n
建立省市地方名称的节点
1 create(n:Province{name:'湖北'}),(:Province{name:'北京'}),(:Province{name:'广东'}) return n
建立股票和证券交易所关系
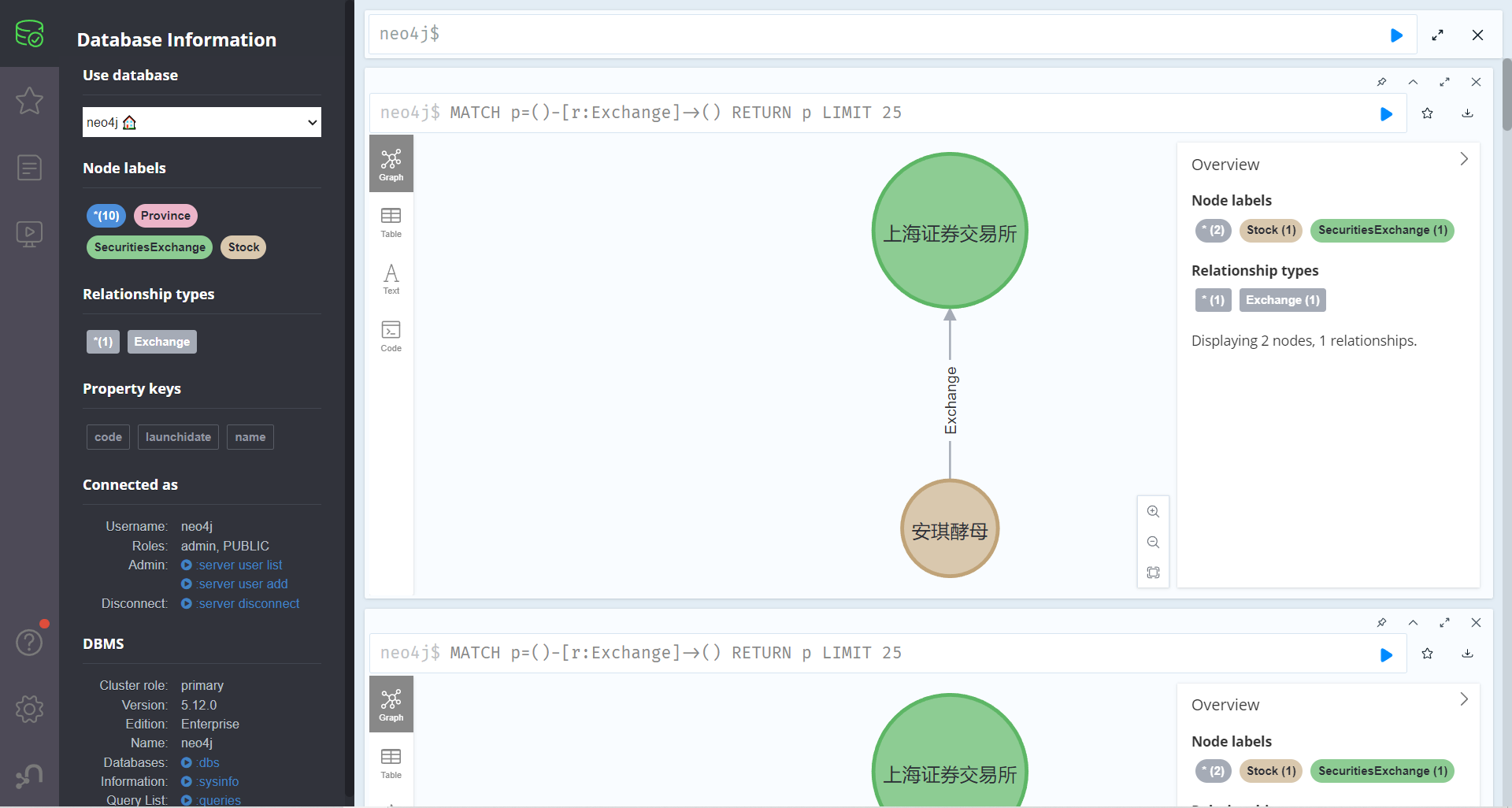
创建股票节点‘安琪酵母’和证券交易所节点‘上海证券交易所’的关系 Exchange
1 match(a:Stock),(b:SecuritiesExhcange) where a.name='安琪酵母' and b.name='上海证券交易所' create(a)-[r:Exchange]->(b) return r
同样用这个方法可创建其他股票节点和证券交易所节点的关系
建立股票和省市名称关系
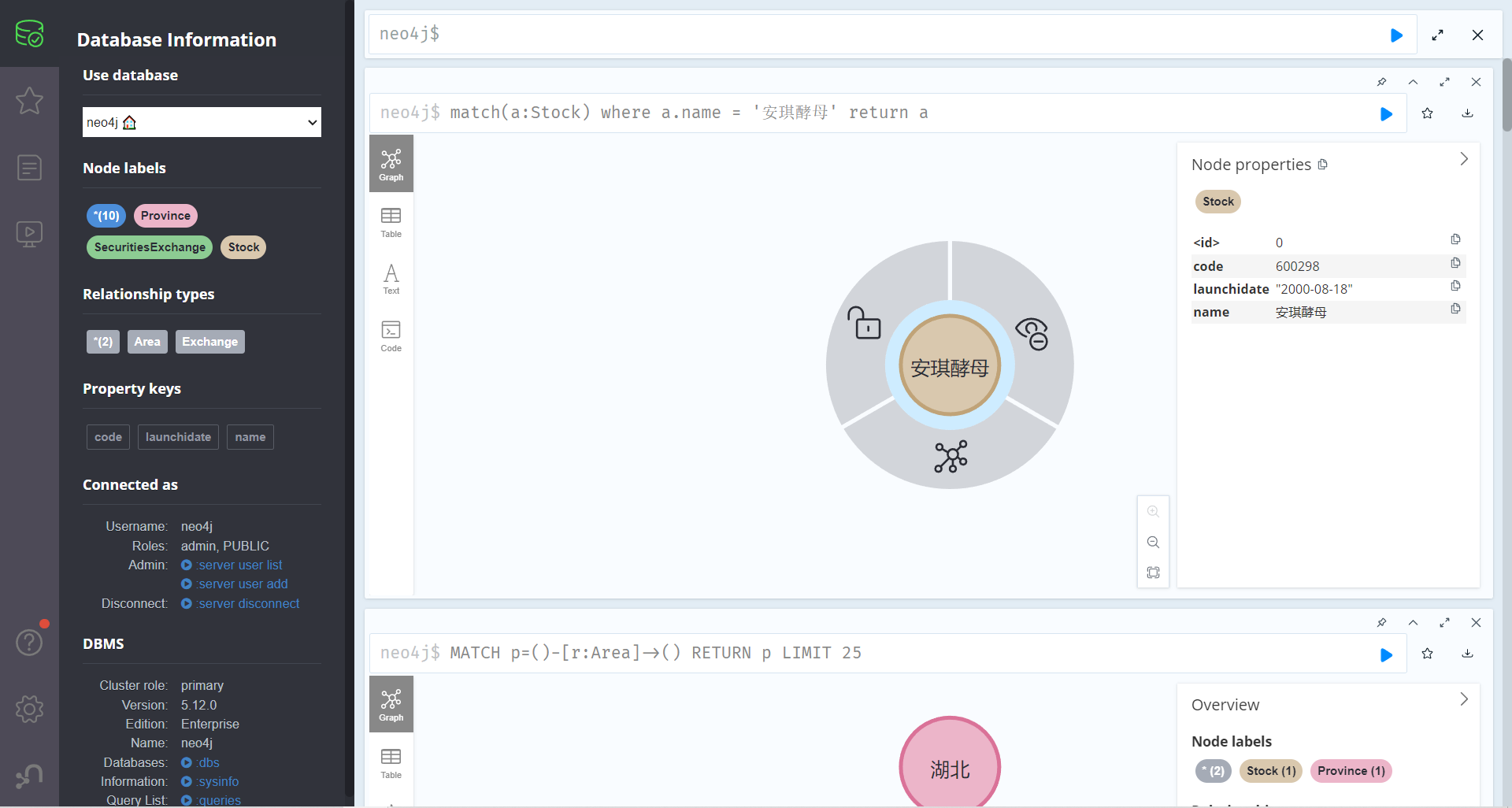
创建股票节点‘安琪酵母’和省市‘湖北’的关系 Area
1 match(a:Stock),(b:Province) where a.name = '安琪酵母' and b.name = '湖北' create (a)-[r:Area]->(b) return r
命令行操作总结 创建一个节点 1 create(n:Stock{name:'安琪酵母',code:'600298',launchDate:date('2000-08-18')}) return n
创建多个节点 1 2 3 4 create(n:Stock{name:'招商银行',code:'600036',launchDate:date('2002-04-09')}), (:Stock{name:'中科创达',code:'300496',launchDate:date('2015-12-10')}), (:Stock{name:'华工科技',code:'000988',launchDate:date('2000-06-09')}), (:Stock{name:'国信证券',code:'002736',launchDate:date('2014-12-29')})
1 create(n:SecuritiesExchange{name:'上海证券交易所'}),(:SecuritiesExchange{name:'深圳证券交易所'})
1 create(n:Province{name:'北京'}),(:Province{name:'湖北'}),(:Province{name:'广东'})
建立关系 1 match(a:Stock),(b:SecuritiesExchange) where a.name = '安琪酵母' and b.name = '上海证券交易所' create (a)-[r:Exchange]->(b) return r
1 match(a:Stock),(b:Province) where a.name = '安琪酵母' and b.name = '湖北' create (a)-[r:Area]->(b) return r
查询某个节点 1 match(a:Stock) where a.name = '安琪酵母' return a
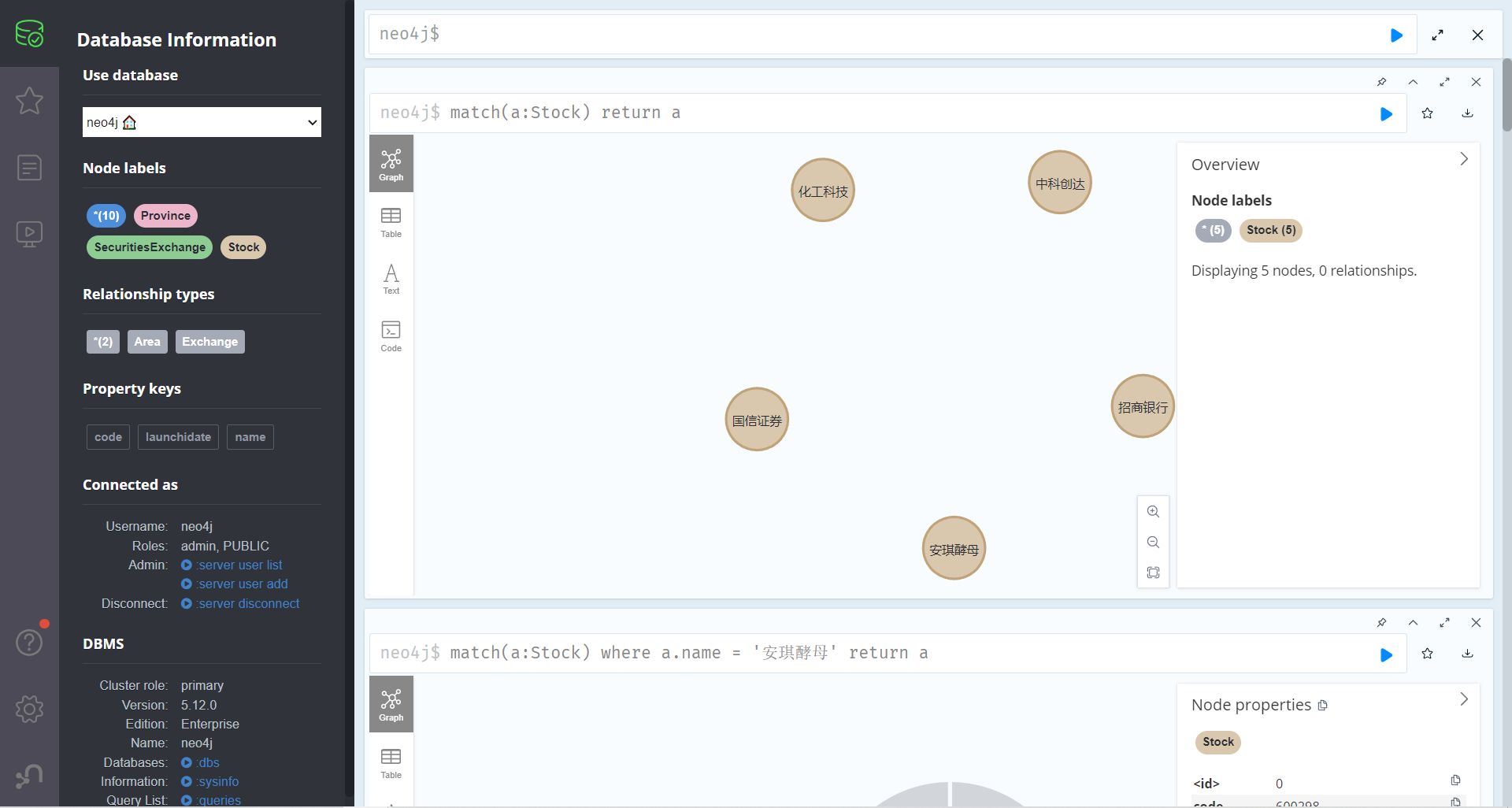
查询某个标签的所有节点
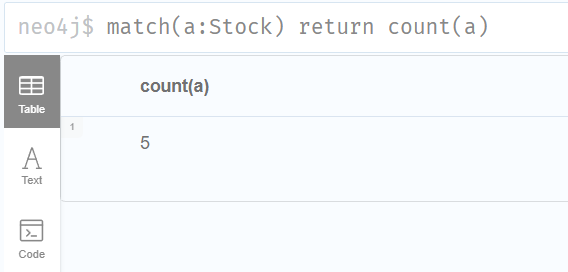
查询某个标签的节点个数 1 match(a:Stock) return count(a)
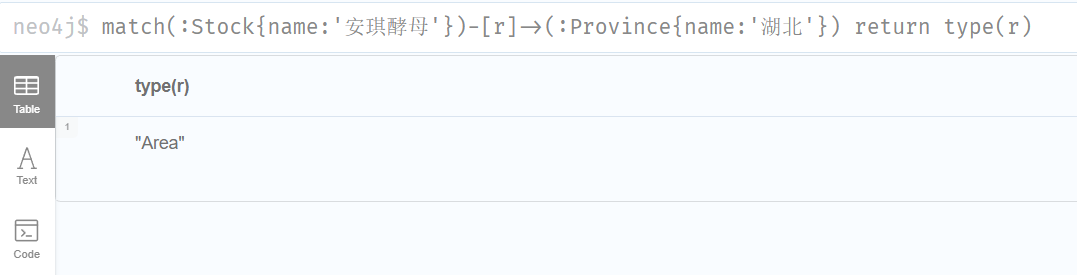
查询两个节点之间的关系类型 1 match(:Stock{name:'安琪酵母'})-[r]->(:Province{name:'湖北'}) return type(r)
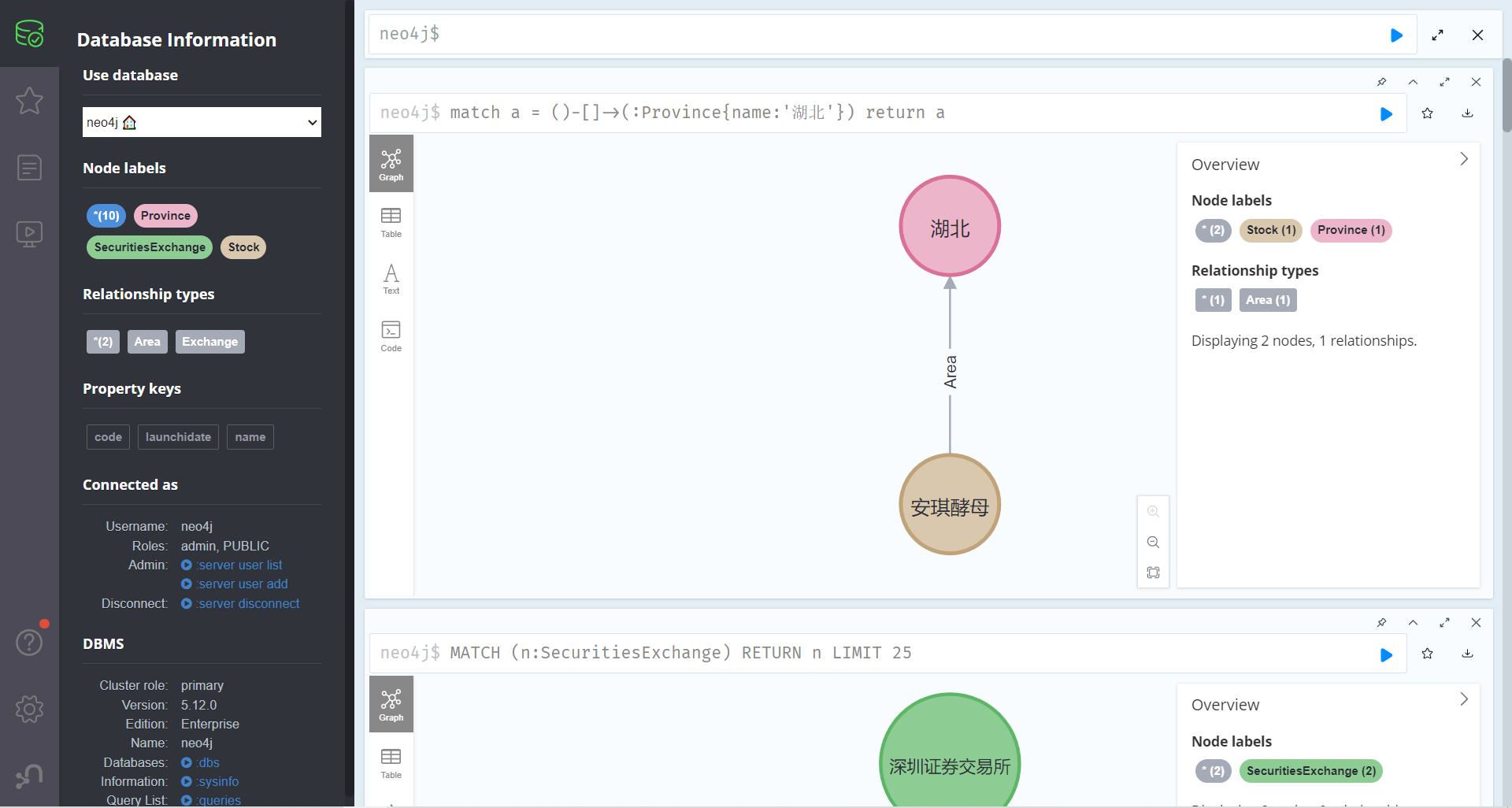
查询某个节点所有的关系 1 match a = ()-[]->(:Province{name:'湖北'}) return a
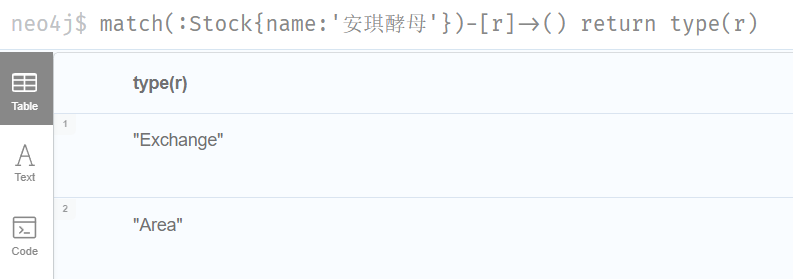
查询某个节点所有的关系类型 1 match(:Stock{name:'安琪酵母'})-[r]->() return type(r)
删除某个节点 1 match(a:Stock) where a.name = '中科创达' delete a
[!attention]
删除某个标签的所有节点 删除所有节点 删除两个节点之间的关系 1 match(:Stock{name:'安琪酵母'})-[r]->(:Province{name:'湖北'}) delete r
删除某个节点的所有关系 1 match(:Stock{name:'安琪酵母'})-[r]->() delete r
删除某个标签的所有关系 1 match(:Stock)-[r]->() delete r
增加节点的属性 set子句
1 match(a:Stock) where a.name = '安琪酵母' set a.abbreviation = 'AQJM' return a
删除节点的属性 remove子句
1 match(a:Stock) where a.name = '安琪酵母' remove a.abbreviation return a
查询某个节点有关的节点和关系 1 match (m)-[r]-(n:Stock{name:'安琪酵母'}) return m,r,n
删除某个节点有关的节点和关系 1 match (m)-[r]-(n:Stock{name:'安琪酵母'}) delete m,r,n
Neo4j Server安装与使用 Neo4j官网下载地址
1 2 3 Server 和 desktop版本的区别在于: desktop拥有良好的可视化,具有跟桌面应用程序一样的操作,可以方便管理多个数据库。 而server则是大量使用命令行来执行CQL语句,同时也可以打开浏览器界面,与desktop的界面是一样的。
添加Neo4j/bin为环境变量
neo4j.bat console Windows环境下,打开命令行界面,同时打开本地网络图形化界面neo4j install-server 安装服务
数据库本地管理 Neo4j安装成功后,会默认安装两个数据库,System和Neo4jneo4j start 启动neo4j stop 关闭
用户管理 在bin目录下,使用cypher-shell连接数据库执行cypher命令
1 2 3 4 5 6 7 8 9 10 11 cypher-shell -d neo4j[数据库名称] -- 需要输入用户名和密码,登录 -- 进入数据库中之后,就可以执行CQL语句进行操作 match(n) return n; -- 查询数据库中所有节点 :help -- 查看当前数据库可以用的指令 :use system -- 使用system数据库 show databases; -- 查看所有数据库(只能在system下操作) :exit -- 退出数据库命令行
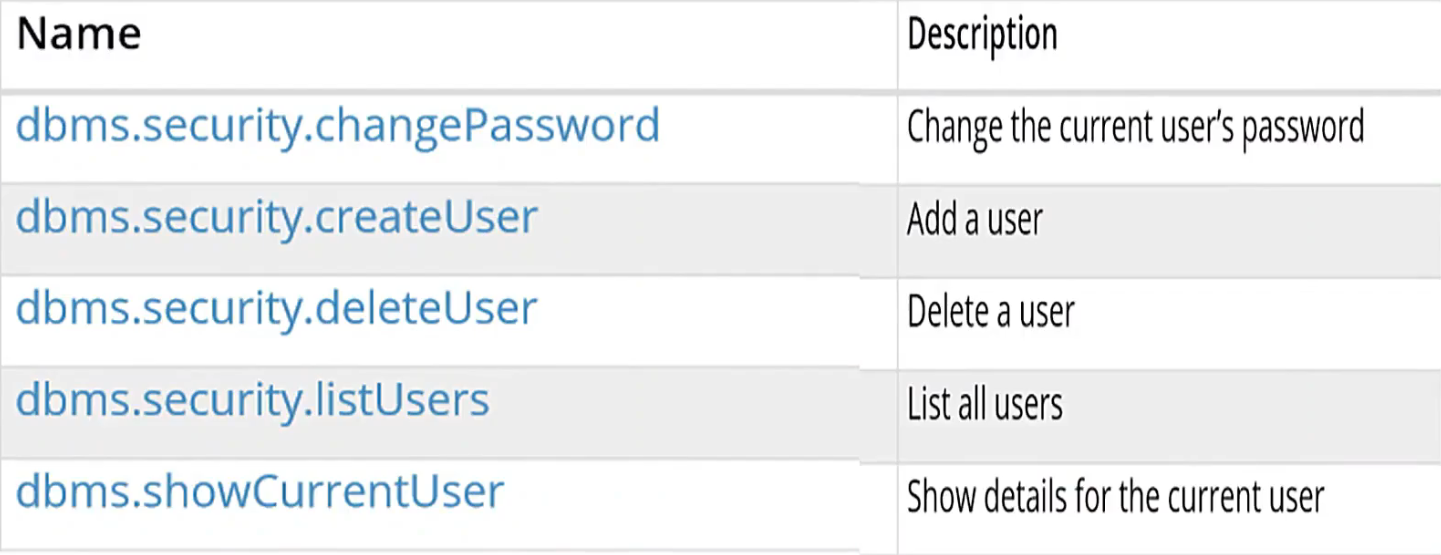
在system下,对于用户进行管理的操作
1 2 3 4 5 6 7 -- 添加用户 CALL dbm.security.createUser(name,password,requirePasswordChange密码改变); -- 示例 CALL dbm.security.createUser('john','123456',true); -- 列出所有用户 CALL dbms.security.listUsers();
数据库的备份和恢复 Neo4j数据库的备份和恢复可以在线或者离线进行
1 2 3 4 5 6 7 8 9 10 11 12 neo4j-admin -h dump/load # 使用帮助 neo4j stop # 先停止服务 1. 离线备份 neo4j-admin dump --database=<database> --to=<destination-path> 示例: neo4j-admin dump --database=neo4j --to=C:\\desktop\\neo4jdata 2. 离线恢复 neo4j-admin load --from=<archive-path> --databse=<database> [--force]存在覆盖 示例: neo4j-admin load --from=C:\\desktop\\neo4jdata --databse=neo4j --force
在Neo4j中批量创建节点和关系 neo4j进阶操作(四)neo4j导入csv,使用load导入csv文件进入neo4j
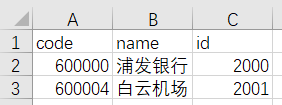
在desktop中用CSV文件导入批量创建节点 CSV文件中的数据,用于演示,实际上数据可以很多
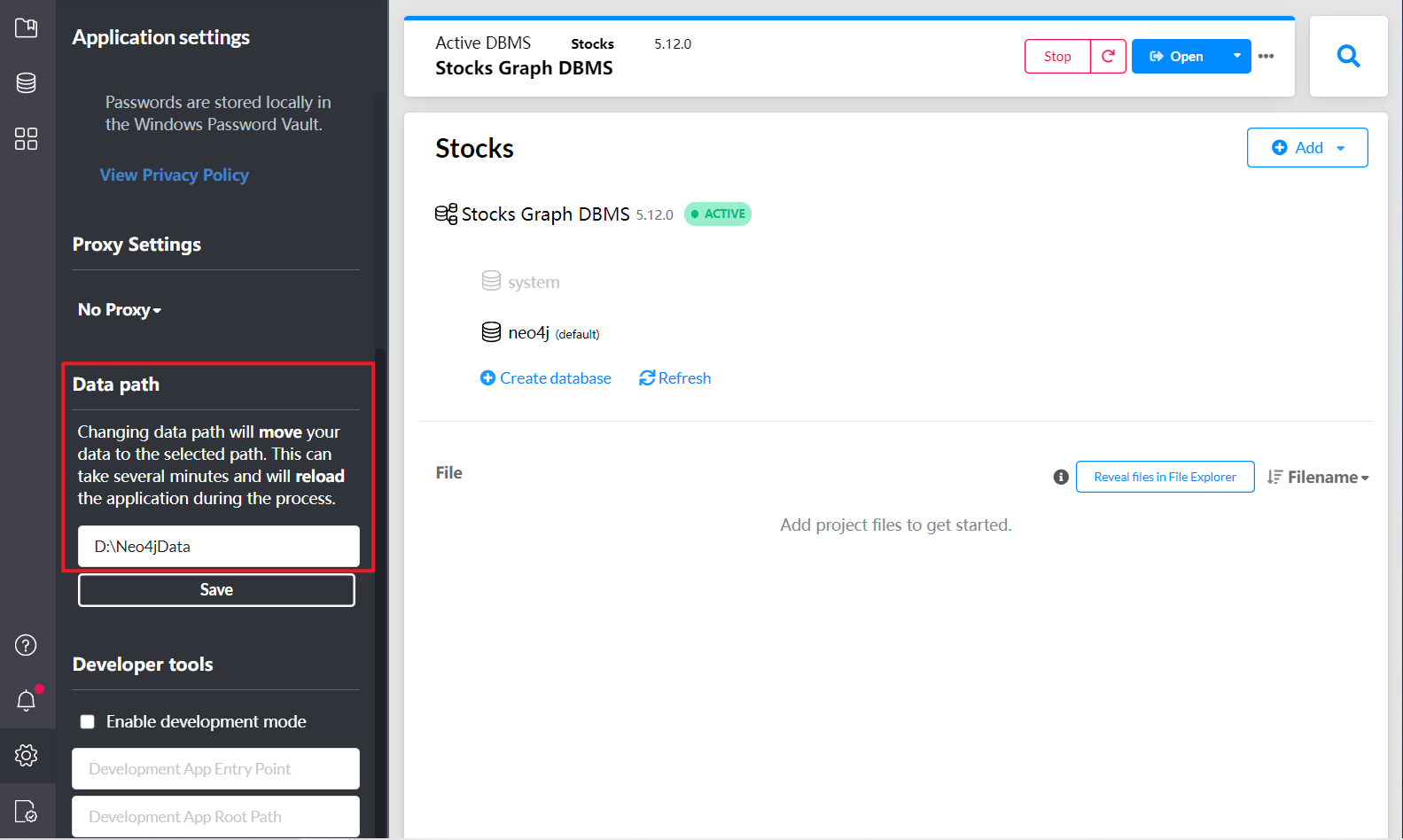
把我们需要导入的CSV数据文件,拷贝到Neo4j的数据目录下
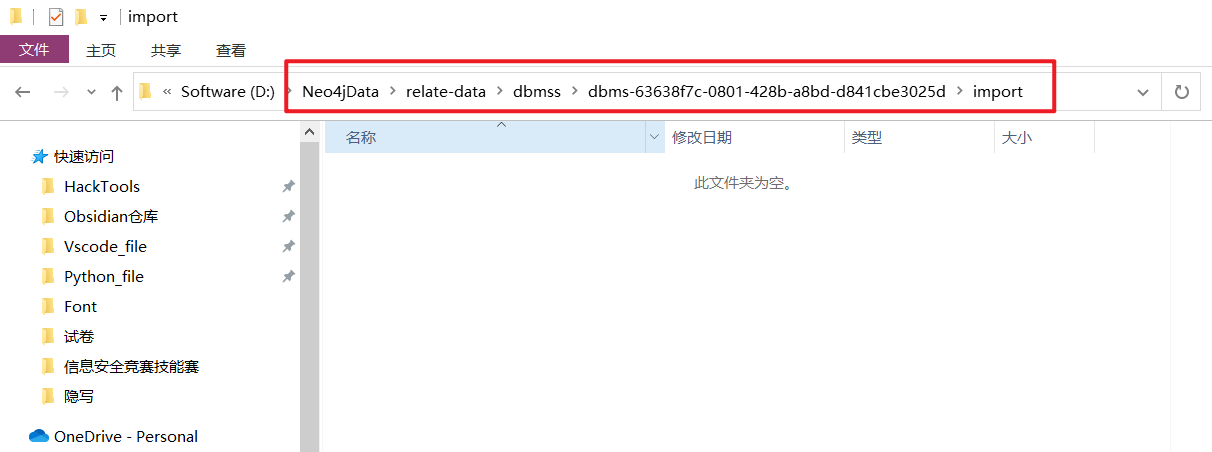
在数据目录下对应数据库的import目录下
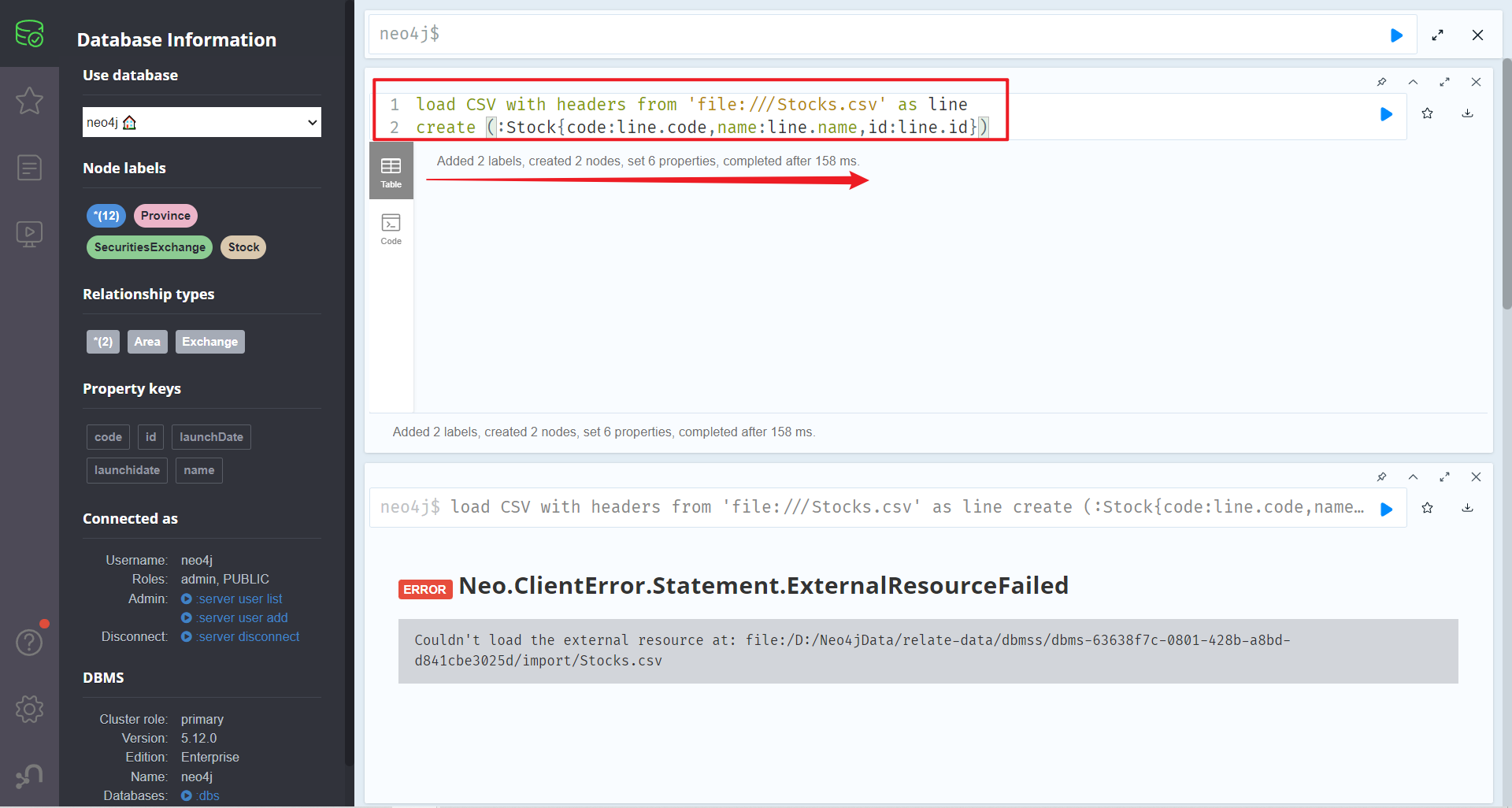
在Neo4j Browser中执行导入命令
1 2 load CSV with headers from 'file:///Stocks.csv' as line create (:Stock{code:line.code,name:line.name,id:line.id})
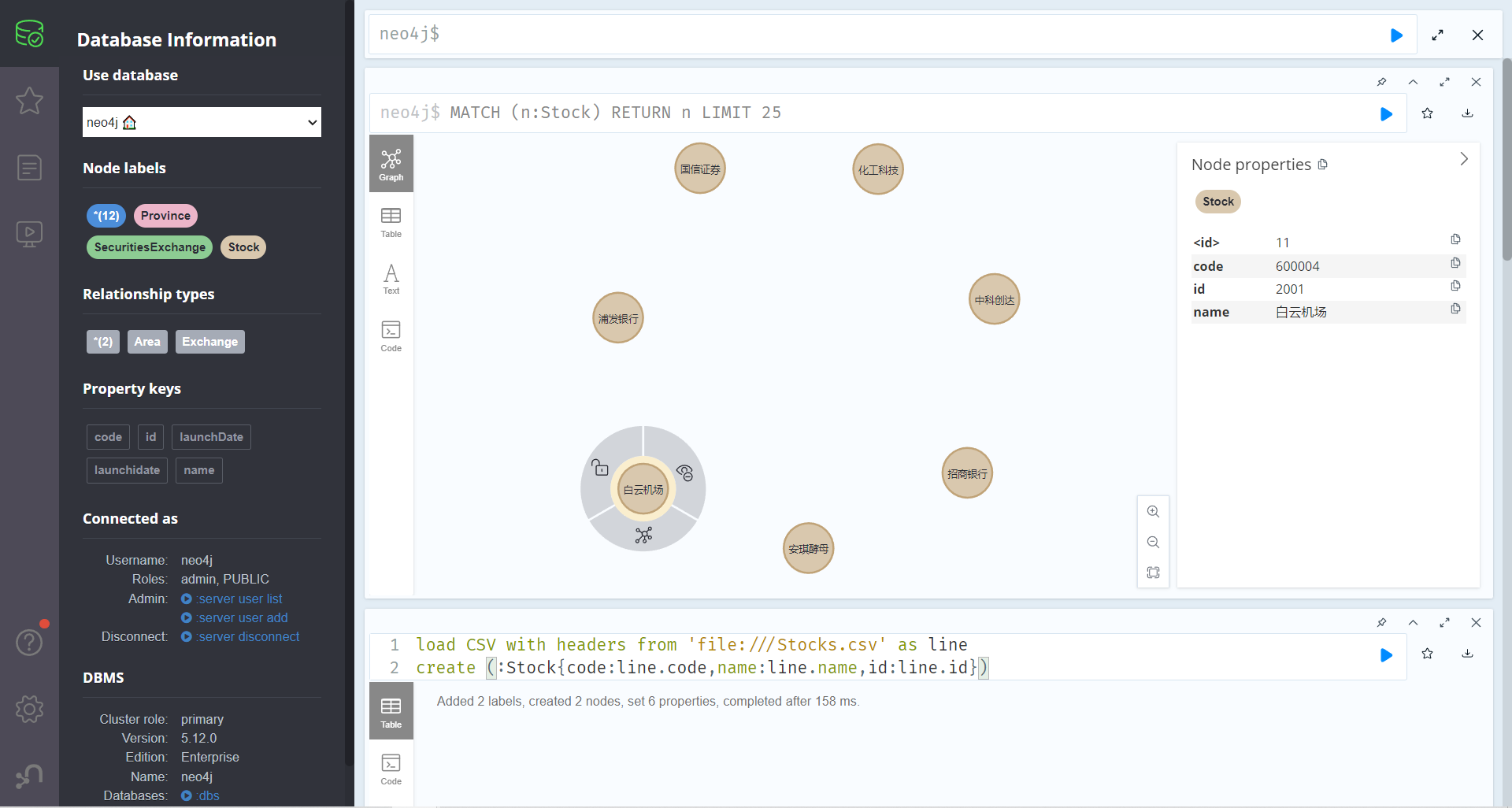
查看节点,导入成功
1 如果导入的数据中出现中文乱码的问题,说明是CSV文件的编码问题,把CSV的编码格式改成UTF-8格式
在desktop中用CSV文件导入批量创建关系 创建股票和证券交易所的关系,先建立CSV文件:(股票代码)(证券交易所id)
同样拷贝到import文件夹中
在Neo4j Browser中执行导入命令
1 2 3 load CSV with headers from 'file:///segx.csv' as line match (from:Stock{code:line.stock_code}),(to:SecuritiesExchange{id:line.exchange_id}) merge (from)-[r:Exchange]->(to)
1 2 3 4 这里一直显示(no changes, no records) 原因在于,这里的交易所节点是之前创建的,在创建的时候并没有设置ID属性,所以在设置关系的时候,并不能以id的方式进行查找匹配节点。 在交易所节点中,属性只有name一个,所以应该用name,或者在交易所节点中增加id属性。 所以在添加关系的时候,应该检查每个节点属性是否匹配
把上诉关系数据文件,改为以code和name进行索引,代码也改为:
1 2 3 load CSV with headers from 'file:///segx.csv' as line match (from:Stock{code:line.code}),(to:SecuritiesExchange{name:line.name}) merge (from)-[r:Exchange]->(to)
1 2 3 4 这里还有一个坑点: 用excel编辑CSV格式的文件是,在Windows下默认保存为Unicode格式,而在Neo4j导入数据的过程中是需要用到UTF-8的格式。所以需要用记事本打开,另存为UTF-8格式。 如果不更改这个格式时,那么导入中文时会乱码,同时属性名可能不能匹配。上面显示(no changes, no records)也是有这样一个原因
完成上面两个关键的步骤,终于可以进行导入
在远程Server中用CSV文件导入批量创建节点和关系(常用) Neo4j笔记(三)Neo4j批量导入数据_neo4j 批量导入数据-CSDN博客
这里远程Server的load导入操作,与本地的desktop的load导入操作基本相同。
远程启动Neo4j Server neo4j start neo4j consolehttp:本机ip:显示端口
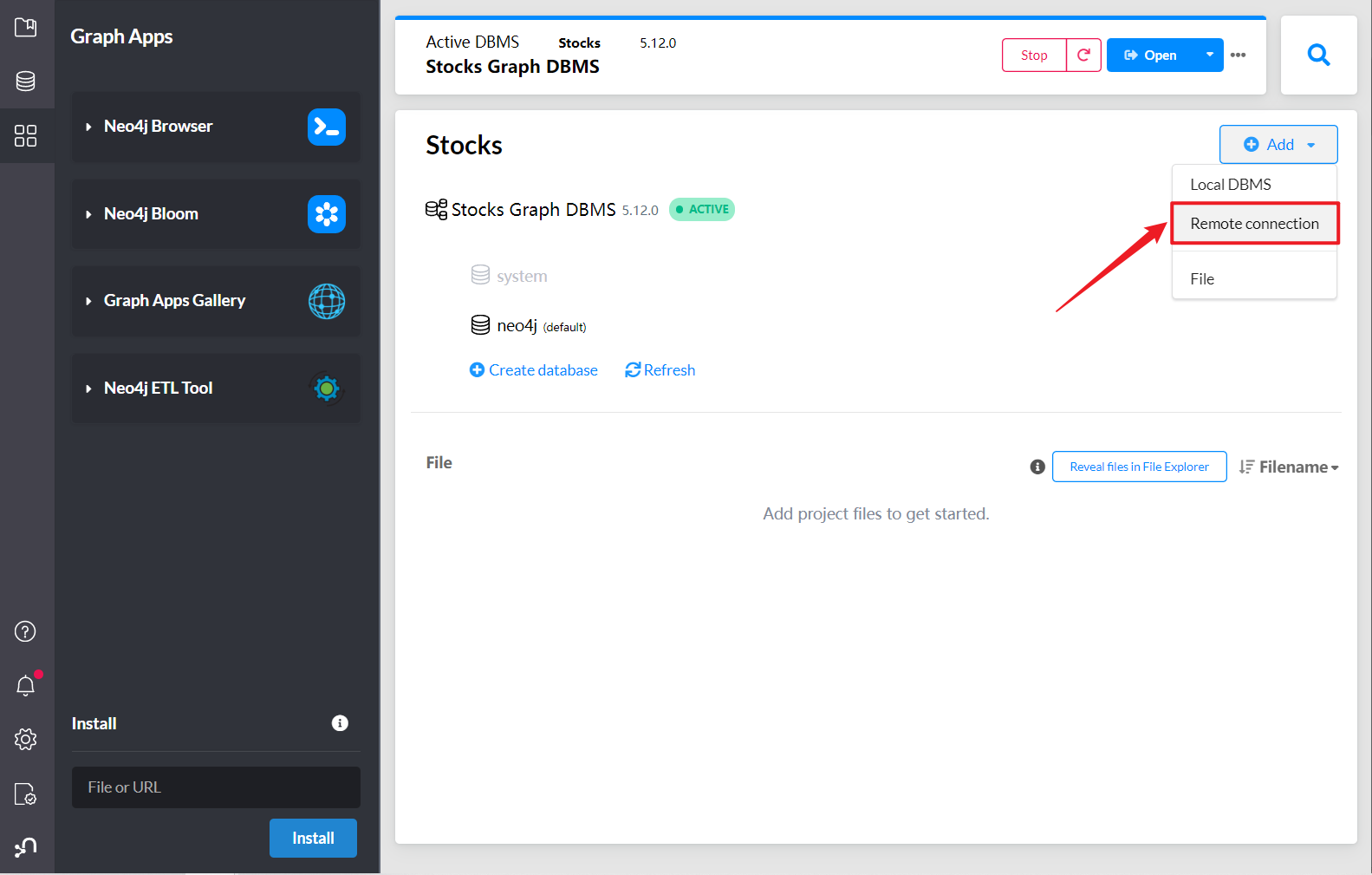
我们也可以用本地neo4j desktop 操作远程的neo4j server
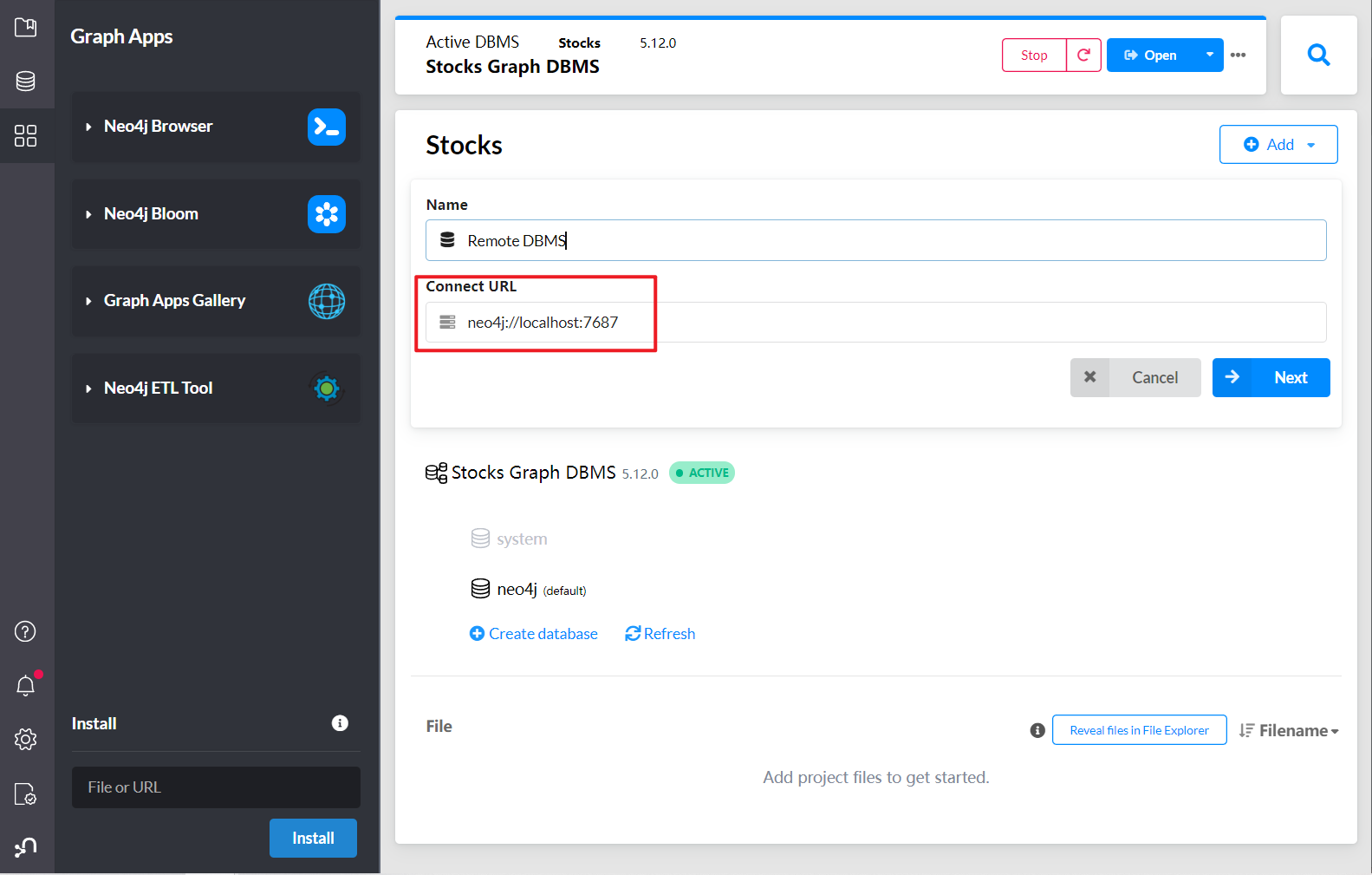
输入服务的IP地址和端口
再输入用户名和密码,即可连接。接下里的导入操作,与desktop的操作是一摸一样的。
Neo4j的Python操作 在远程服务器上安装并创建Neo4j 对于Neo4j 4版本 需要有JDK11的环境,而对于Neo4j 5版本,需要有JDK17/21的环境
neo4j console 启动服务(前台)neo4j start 启动服务(后台)neo4j stop 停止服务
通过本地浏览器登录
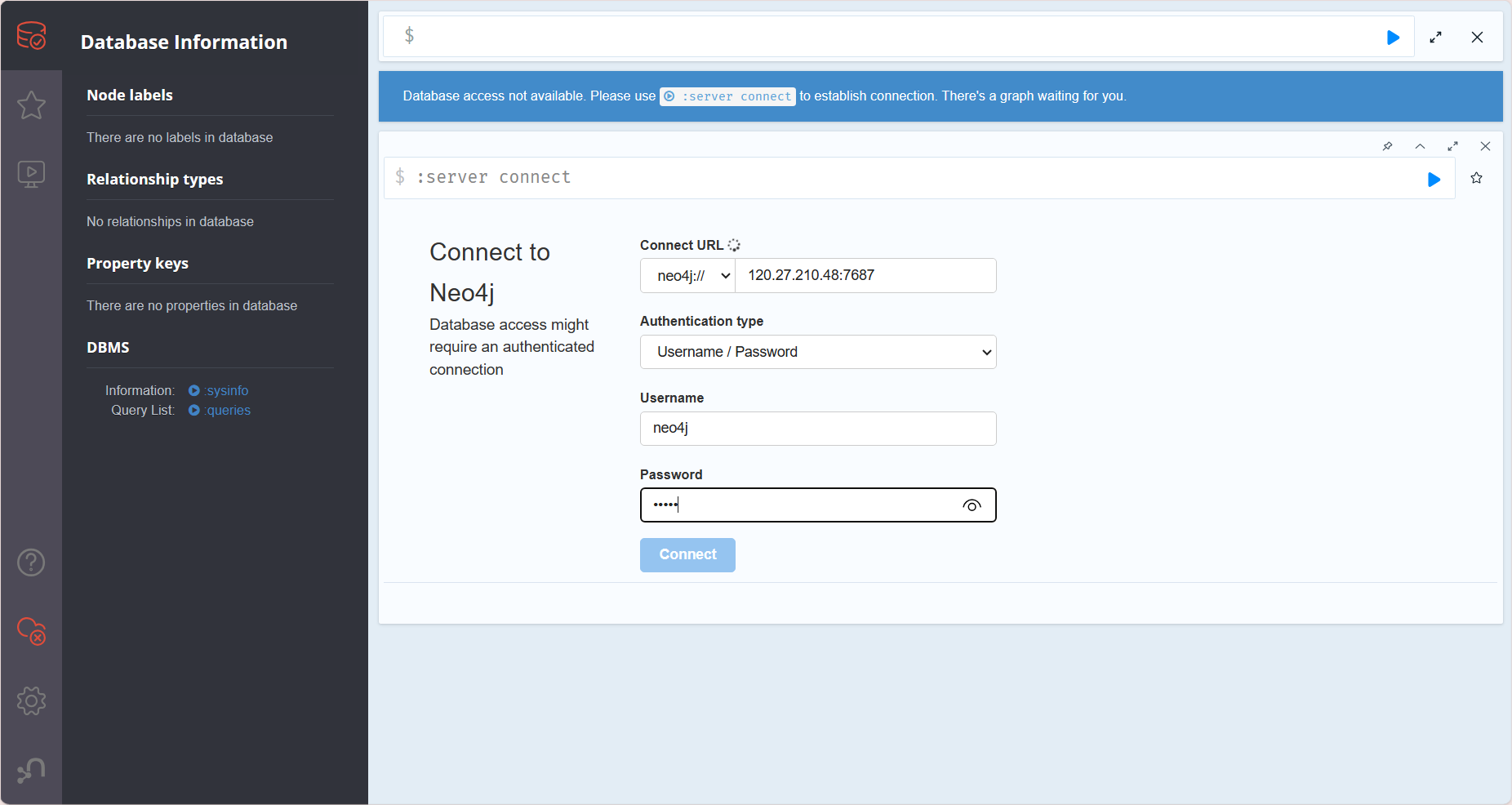
接着我们可以使用本地的desktop进行远程的数据库连接
输入用户名和密码,并登录连接
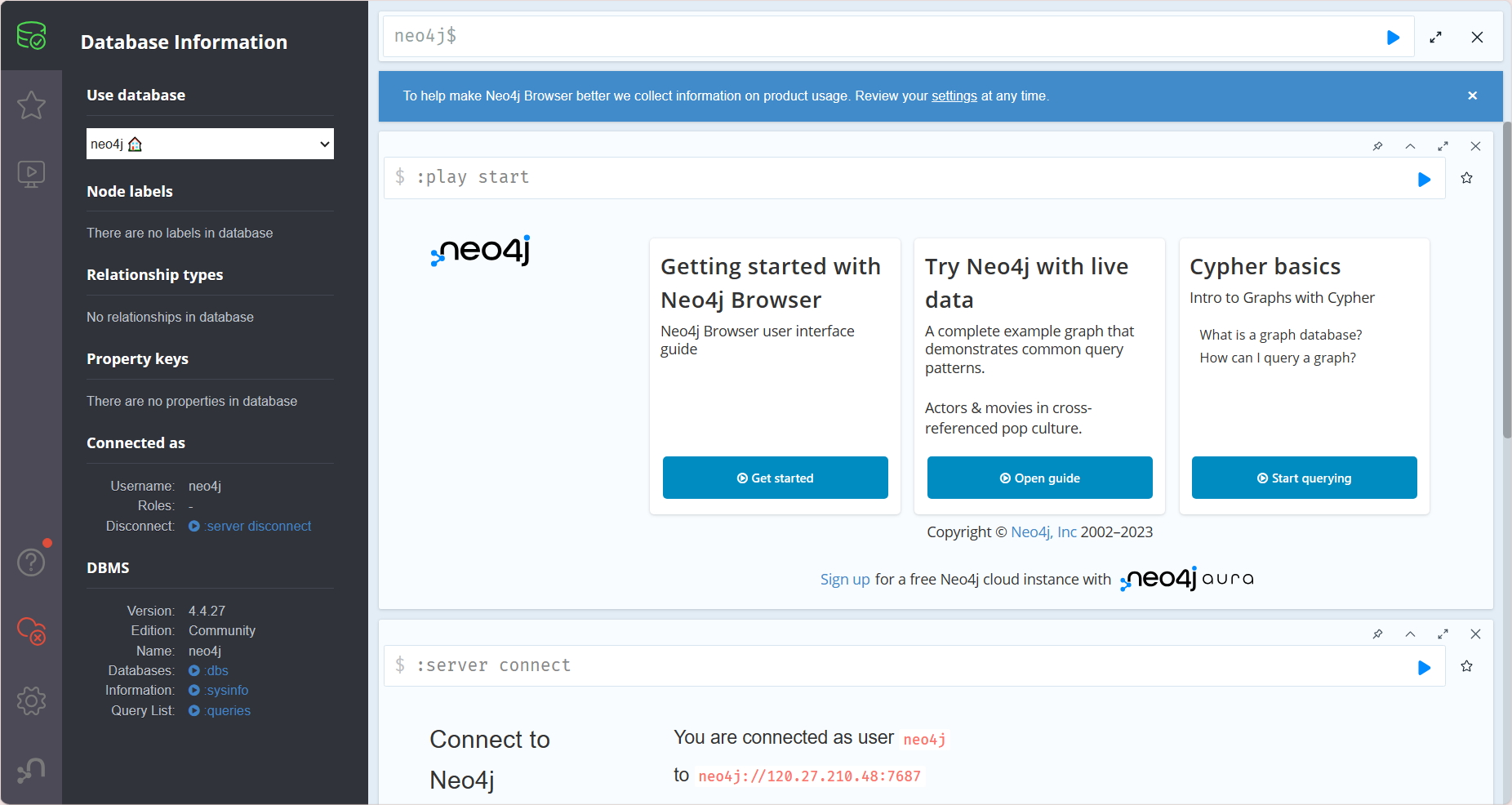
成功打开远程数据库,图形化界面
利用Python读取excel数据创建节点 python导入:Neo4j入门(二)批量插入节点、关系_neo4j批量创建关系-CSDN博客
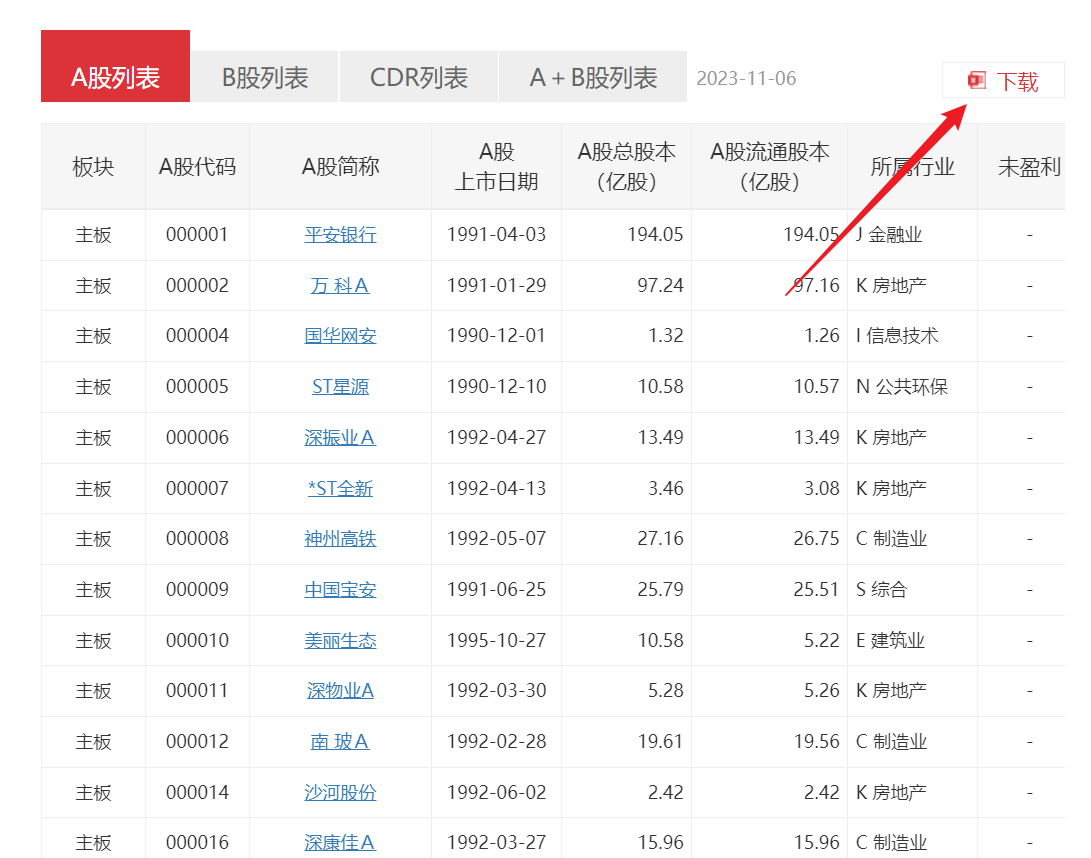
1. 数据准备,在深圳证券交易所官网下载股票列表Excel文件
http://www.szse.cn/market/product/stock/list/index.html
当然也直接使用Python代码,进行下载,下载连接为:http://www.szse.cn/api/report/ShowReport?SHOWTYPE=xlsx&CATALOGID=1110&TABKEY=tab1&random=0.410442009042401
1 2 3 4 5 6 7 8 9 10 from urllib import requestdef DownloadExcel (url ): down_path = 'A股列表.xlsx' request.urlretrieve(url, down_path) url = 'http://www.szse.cn/api/report/ShowReport?SHOWTYPE=xlsx&CATALOGID=1110&TABKEY=tab1&random=0.410442009042401' DownloadExcel(url)
得到一个A股列表Excel文件
2. 用Python读取Excel文件数据,在Python中使用Cypher命令,在Neo4j中批量建立节点
py2neo · PyPI py2neo基本用法 python - 使用Py2neo在Neo4j中创建节点和关系 Python–pandas读取excel Python读写Excel——Pandas
接着编写Python代码,实现读取文件数据,并通过Cypher语句写入到数据库中去。这里使用远程Neo4j Server版本。
1 2 3 需要注意的是: 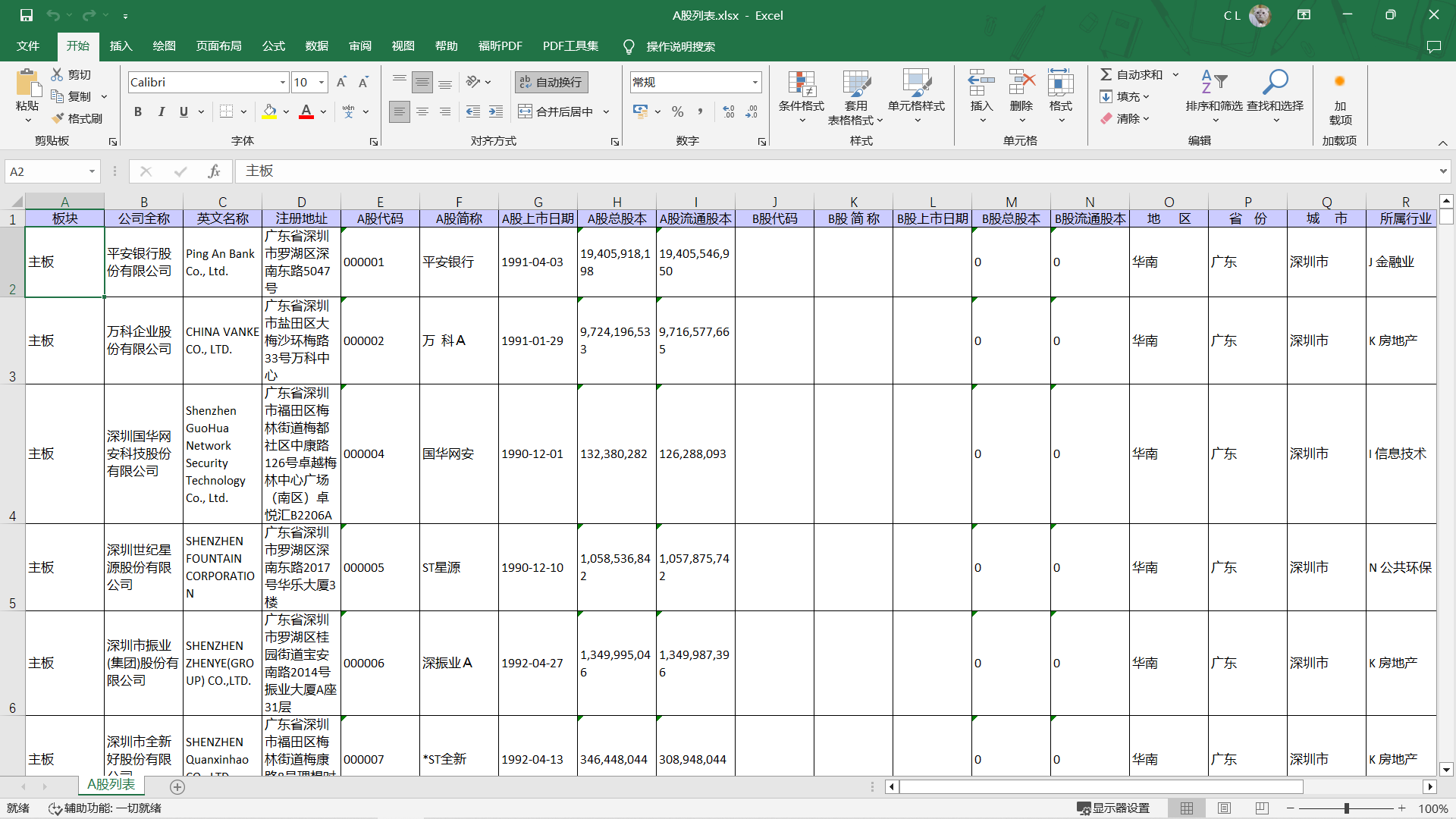
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import timeimport pandas as pdfrom py2neo import Graph, Node, Relationship, NodeMatcher, RelationshipMatcher, Subgraphdef ReadExcel (): read_path = 'A股列表.xlsx' df = pd.read_excel(io=read_path) return df url = "bolt://serverIP:port" username = "neo4j" password = "password" graph = Graph(url, auth=(username,password)) print ("neo4j info: {}" .format (str (graph)))s_time = time.time() node_count = 0 df = ReadExcel() print (f'总数据量:{len (df)} ' )label = 'A股' for i in range (0 , len (df)): Plate = df.iloc[i]['板块' ] FullName = df.iloc[i]['公司全称' ] EnName = df.iloc[i]['英文名称' ] Address = df.iloc[i]['注册地址' ] Code = df.iloc[i]['A股代码' ] ShortName = df.iloc[i]['A股简称' ] Date = df.iloc[i]['A股上市日期' ] Area = df.iloc[i]['地 区' ] Province = df.iloc[i]['省 份' ] City = df.iloc[i]['城 市' ] Industry = df.iloc[i]['所属行业' ] Cypher = f"merge(:{label} {{Plate:'{Plate} ',FullName:'{FullName} ',EnName:'{EnName} ',Address:'{Address} ',Code:'{Code} ',ShortName:'{ShortName} ',Date:'{Date} ',Area:'{Area} ',Province:'{Province} ',City:'{City} ',Industry:'{Industry} '}})" graph.run(Cypher) node_count = + 1 print ('节点数量:' + node_count)e_time = time.time() print (f'创建节点耗时:{e_time - s_time} s' )
再次登上浏览器的图形化界面,发现已经创建成功
Py2neo V4 中文文档 官方链接已失效
利用子图创建节点和关系
1 2 3 4 5 6 7 8 from py2neo import Node,Relationship,Graph,Subgraphgraph = Graph("http://localhost:7474" ,auth=("neo4j" ,"123456" )) a = Node("Person" , name="Alice" ) b = Node("Person" , name="Bob" ) c = Node("Person" , name="Jim" ) d = Node("Person" , name="Nacy" ) nodes=Subgraph([a,b,c,d]) graph.create(nodes)
1 2 3 4 5 6 7 8 9 10 a=graph.nodes.match ("Person" ,name="Alice" ).first() b=graph.nodes.match ("Person" ,name="Bob" ).first() c=graph.nodes.match ("Person" ,name="Jim" ).first() d=graph.nodes.match ("Person" ,name="Nacy" ).first() rel_a=Relationship(a,"likes" ,b) rel_b=Relationship(b,"likes" ,a) rel_c=Relationship(c,"likes" ,d) rel_d=Relationship(d,"likes" ,c) A=Subgraph(relationships=[rel_a,rel_b,rel_c,rel_d]) graph.create(A)
Py2neo:一种快速导入百万数据到Neo4j的方式_python 导入neo4j 节点id-CSDN博客
根据上方A股列表的数据,重新编写代码,创建实体节点和关系
遇到的问题:
创建节点的属性,必须是字符串类型的,不然会报错。DataFrame读出来的数据有可能会是int或者numint64类型,需要进行转换
创建关系时进行节点的查找匹配十分耗时,所以可以采用子图的形式进行创建 (查询节点和关系很费时间)
没有报错,但是创建不出来关系,就需要检查匹配条件是否正确,不正确的话匹配不到节点,就不能创建关系
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 import timeimport pandas as pdfrom py2neo import Graph, Node, Relationship, NodeMatcher, RelationshipMatcher, Subgraphdef ReadExcel (): read_path = 'A股列表.xlsx' df = pd.read_excel(io=read_path) return df url = "bolt://serverIP:port" username = "neo4j" password = "password" graph = Graph(url, auth=(username,password)) nodes = NodeMatcher(graph) print ("neo4j info: {}" .format (str (graph)))graph.delete_all() s_time = time.time() node_count = 0 df = ReadExcel() print (f'总数据量:{len (df)} ' )label = 'A股' a_list = [] plate_set = set ({}) area_set = set ({}) province_set = set ({}) city_set = set ({}) industry_set = set ({}) relationships_list = [] nodes_list = [] for i in range (0 , len (df)): dict = { 'Plate' : str (df.iloc[i]['板块' ]), 'FullName' : str (df.iloc[i]['公司全称' ]), 'EnName' : str (df.iloc[i]['英文名称' ]), 'Address' : str (df.iloc[i]['注册地址' ]), 'Code' : str (df.iloc[i]['A股代码' ]), 'ShortName' : str (df.iloc[i]['A股简称' ]), 'Date' : str (df.iloc[i]['A股上市日期' ]), 'Area' : str (df.iloc[i]['地 区' ]), 'Province' : str (df.iloc[i]['省 份' ]), 'City' : str (df.iloc[i]['城 市' ]), 'Industry' : str (df.iloc[i]['所属行业' ]) } plate_set.add(str (df.iloc[i]['板块' ])) area_set.add(str (df.iloc[i]['地 区' ])) province_set.add(str (df.iloc[i]['省 份' ])) city_set.add(str (df.iloc[i]['城 市' ])) industry_set.add(str (df.iloc[i]['所属行业' ])) a_list.append(dict ) a_dict = {} for i in range (0 , len (a_list)): node = Node(label, ShortName=a_list[i]['ShortName' ], FullName=a_list[i]['FullName' ], EnName=a_list[i]['EnName' ], Code=a_list[i]['Code' ], Address=a_list[i]['Address' ], Date=a_list[i]['Date' ], Plate=a_list[i]['Plate' ], Area=a_list[i]['Area' ], Province=a_list[i]['Province' ], City=a_list[i]['City' ], Industry=a_list[i]['Industry' ]) graph.create(node) a_dict[f'{a_list[i]["Code" ]} ' ]=node node_count = + 1 plate_dict = {} area_dict = {} province_dict = {} city_dict = {} industry_dict = {} label = '板块' for plate in plate_set: node = Node(label, name=plate) graph.create(node) plate_dict[f'{plate} ' ]=node node_count = + 1 label = '地区' for area in area_set: node = Node(label, name=area) graph.create(node) area_dict[f'{area} ' ]=node node_count = + 1 label = '省份' for province in province_set: node = Node(label, name=province) graph.create(node) province_dict[f'{province} ' ]=node node_count = + 1 label = '城市' for city in city_set: node = Node(label, name=city) graph.create(node) city_dict[f'{city} ' ]=node node_count = + 1 label = '行业' for industry in industry_set: node = Node(label, name=industry) graph.create(node) industry_dict[f'{industry} ' ]=node node_count = + 1 relationships_list = [] for i in a_list: node1 = a_dict[f'{i["Code" ]} ' ] node2 = plate_dict[f'{i["Plate" ]} ' ] relationships_list.append(Relationship(node1, '板块' , node2)) node2 = area_dict[f'{i["Area" ]} ' ] relationships_list.append(Relationship(node1, '地区' , node2)) node2 = province_dict[f'{i["Province" ]} ' ] relationships_list.append(Relationship(node1, '省份' , node2)) node2 = city_dict[f'{i["City" ]} ' ] relationships_list.append(Relationship(node1, '城市' , node2)) node2 = industry_dict[f'{i["Industry" ]} ' ] relationships_list.append(Relationship(node1, '行业' , node2)) sub = Subgraph(relationships=relationships_list) tx_ = graph.begin() tx_.create(sub) graph.commit(tx_) print (f'节点数量:{node_count} ' )e_time = time.time() print (f'创建节点耗时:{e_time - s_time} s' )