Python爬虫之蓝奏云文件批量下载
起源
最近刚好入门了Python爬虫,在此之前系统完整的学了Python的基础入门知识,学习爬虫顺便也可以巩固之前学习的Python基础知识。
学习Python爬虫,先去看了B站的介绍视频,很短,只有4个小时,我也没有做笔记,就直接2个小时看完,学会了Python的request请求,网页的知识之前在HTML和CSS学习过了。所以感觉还是比较简单的,跟着视频做了爬取豆瓣TOP250电影名的小项目。其他的就一点都没学过。
接着我就遇到了一个问题,我想要批量下载B站UP主分享在蓝奏云上的文件,资源很丰富,文件资料很多,一个个下载就很慢很费劲,我就想着能不能用Python爬虫完成这个小项目
项目文件地址
过程
我先把需要的5个链接和对应的密码,复制保存到本地的文本里。如何通过Python进行整理和格式化。
1 | MIUI解bl锁和刷机相关工具: |
提取其中的标题作为文件夹名,链接和密码,分别存在两个列表中,索引一一对应,方便后续的操作。并把这一步操作分装成一个函数。
1 | # 整理链接地址 |
接着就是变量这两个列表,分别访问对应的分享文件链接,这里需要注意的是,这里的分享链接,里面还有很多的文件。
先用request请求链接,这里遇到了我第一个问题,就是我们应怎么把密码输入进去。查看源码,发现是一个输入框input接收密码,但是我是应该直接把密码写在这个文本框中还是直接get或者post请求。
源码看着看着,我找到了答案。这里网页用了ajax的post请求,把一堆参数(我也不知道是什么)里面包含pwd,也就是我们输入的密码,一起提交上去。所以我的方向就是,用request的post方法进行请求。准备data和headers的过程中,我发现这个data里面的其他参数也变动的,每次请求都不一样,那我该怎么写这个参数。于是我又去看JavaScript的代码,发现里面竟然有这些参数,这些参数全部都是通过js代码中的ajax请求上去,参数的值也都写在上面,那么我的思路就是先请求当前这个网页,从网页中拿到js中的参数。
但是在操作的过程中,我发现Python中的request根本请求不到js代码,只有js的链接地址,跟网页的元素查看器显示的不一样。上网搜索发现,request请求的是网页渲染之前的代码,当然不可能有js代码,这就是我遇到的第二个问题。
这个问题我想的有点久,最后我想到的是,可以不可以通过获取script标签上面的div标签,在通过div的下一个兄弟标签来获取script标签,因为div标签是在网页渲染前就已经存在了,而且这样的方法在JavaScript的代码中经常会用到。
于是我试着去操作一下,发现是真的可行的,==不过也不知道其中的原理是什么。== 拿到了script标签中的内容,接下来就是提取我们需要的信息,这里就是考察我对字符串的各种操作的熟悉程度,于是我的写法是这样的。
1 | def get_key(url: str): |
利用拿到的这些参数,我就可以用post请求了,这里请求的源地址是source_url = 'https://wwr.lanzoui.com/filemoreajax.php'
这样我就拿到了Ajax返回来的一整个json数据,我转成字典,发现这里面的数据全都是这个分享链接下的所有文件的信息,包括文件名、文件id(可以拼接成下载链接)等等信息。
于是我又利用字典的知识,把整个json数据中的文件名和文件id分别存在各自的列表中,同样分装成函数,并返回这两个列表。
1 | def get_download_id(t: str, k: str, f: str, u: str, pwd: str): |
接下来,就是根据拼接成的文件下载链接,进行下载。这里遇到了第三个问题。我们用浏览器访问下载链接,发现了这个页面又三个下载按钮,分别是联通下载、电信下载、普通下载,这三个标签套在同一个a标签中😄,然后这三个按钮又是属于另外一个HTML页面,通过链接显示在这个页面中,于是我直接请求那三个按钮的页面,进行操作。
有趣的是,这里的下载按钮同样是用Ajax请求的,我同样按照上面的方法,先找到div标签,再用下一个兄弟的下一个兄弟获取到了script中的内容,这个内容里面有我所需要的data参数的值,同样字符串操作获得了值,并封装成函数返回这些参数。
1 | def get_ajaxdata(download_url: str): |
用上面得到的参数进行post请求,就可以得到Ajax返回的一个json数据,进行数据分析,这里我们就得到了文件下载的直链了,只要点击这个链接,浏览器就可以开始自动下载。
接下来的事情就简单了,只要get请求这些链接,把返回值写入文件中。这里我用标题创建了文件夹,把每个文件命名为之前返回的文件名,这样一切就完美了。但是在这里我遇到了最困难的问题,也是卡的时间最久的一次。
就是按照我的想法这样操作,根本行不通,下载下来的文件都是5kb,而且打不开,根本就不是我想要的文件。于是我开始分析,先把返回值打印出来,发现是一个html格式的文本,难怪不对。我当时就在想难道我这个链接不是文件的直链?但是浏览器一打开就可以下载,也不对啊。于是我认为是大文件没有分批下载,于是我把写入文件代码改成
1 | with open(dir_name + '/' + file_name_all[0], 'wb') as fp: |
但是还是不行,之后我又尝试了很多方法,都不行,上网搜索了很多Python请求文件的方法,也都不行。最后我几乎都认定我得到的这个链接不是文件的直链,我用Firefox浏览器打开,跳出来一个页面,有一个下载按钮,于是我又开始像前面的操作一样分析代码,但是我又被卡住了,明明用正确的data却请求不到数据。
最后我上网搜索到了别人写的蓝奏云下载的爬虫,我发现链接确实是直链,因为别人也是用这个链接下载的,唯一的不同就是,下载时的请求不同,还有写了一堆请求头。问题就这样解决了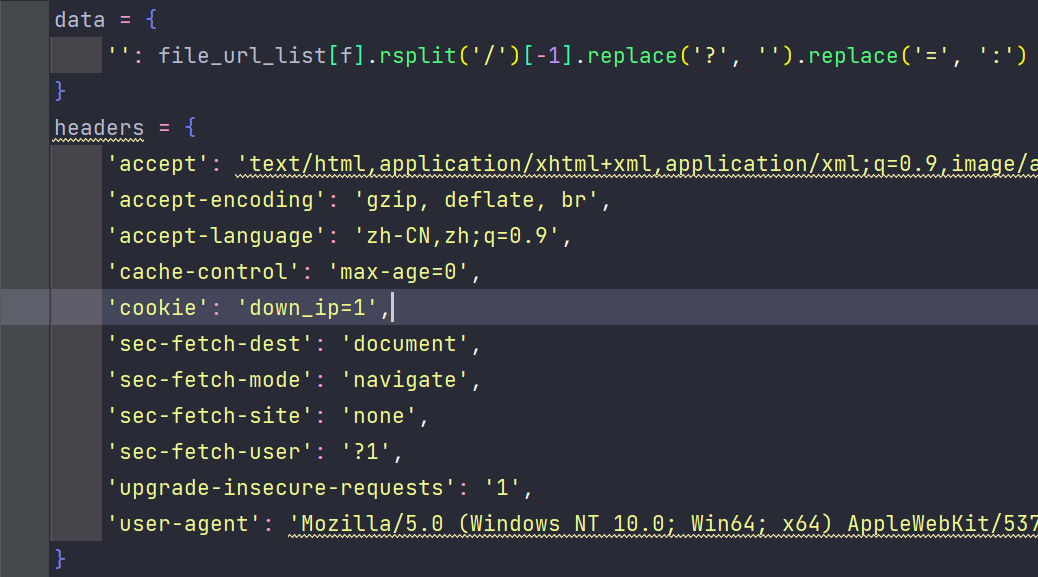
最后根据网上的方法,我也成功把文件下载下来。
反思
我这个程序,写的看起来就像屎山,以后再回来说不定就读不懂了。所以养成良好的编码习惯还是很有必要的。可以多参考别人写的好的代码格式,也可以看Python的编码规范。
这里面的代码,还有很多的原理问题需要解决和思考
- 最后问题的解决,原理到底是什么?
- Python请求链接下载文件的方法有多少种?
- 获取script标签的操作肯定不是标准的写法,但是这样能成功的原理是什么?Python爬虫遇到这种情况,规范正确的解决方法是什么?
- ……
这样问题应该可以在我系统学习了Python爬虫之后得到解决。





